Assignment 4: Univariate data analysis#
Now that you’ve successfully navigated our “crash course” in Python programming, it is time to put those skills to use working with real data, the focus of this course. Python is an extraordinarily powerful tool for working with data, facilitated in large part by the external libraries of code produced by the Python community for data analysis and visualization. We’re going to be working with a few of those libraries this semester, starting with this notebook.
In our data analysis assignments, you’ll be working with real-live data - as in many real-world projects! Further, the data that we find on the web often needs a little bit - or a lot - of modification before we can do anything analytically useful with it. You will start to get some experience with that today, and things will get progressively more challenging throughout the semester.
Working with external data in Google Colab#
Our data for this assignment, adult overweight/obesity rates by state, come from the Kaiser Family Foundation. The data file, a comma-separated values file called adult_data.csv, can be downloaded from TCU Online or the course GitHub repository.
There are a couple ways to get external data into your Google Colab session. The quickest way is to upload data directly to your Colab session by clicking the Files icon on the left-hand side of the screen then clicking the “Upload to session storage” icon (the one on the left). You can then navigate to where you’ve downloaded the adult_data.csv file and upload it to your session.
Once you’ve uploaded the data, you should see your file adult_data.csv appear in the file browser. This allows you to read in the data that you’ve downloaded as a pandas DataFrame. Right-click the CSV file in the file browser then choose “Copy path”. Replace the path to the dataset in the code chunk below with this path by pasting it there.
In class, we discussed the Python package pandas, which allows uses to work with data in a tabular structure, with individual observations organized as rows and data attributes organized as columns. Use the cell below to load pandas with the import statement and read in your data. We’ll be calling our data frame here df, short for data frame.
import pandas as pd
df = pd.read_csv("data/adult_data.csv")
df.head()
| state | all_adults | male | female | |
|---|---|---|---|---|
| 0 | Alabama | 0.697 | 0.721 | 0.674 |
| 1 | Alaska | 0.642 | 0.703 | 0.568 |
| 2 | Arizona | 0.647 | 0.710 | 0.583 |
| 3 | Arkansas | 0.705 | 0.721 | 0.688 |
| 4 | California | 0.622 | 0.681 | 0.560 |
So what did you just do here? You imported in the code associated with the pandas library, which will be referenced by the prefix pd. You then used the read_csv() function from the pandas library to convert the CSV of overweight rates by state into a pandas DataFrame. By default, read_csv() assumes that the first row of your CSV represents column headings, and then rows 2 until the end represent data.
One issue with this approach to reading in data is that your data are not persistent. Google Colab will recycle workspaces to save space, which means that when you return to work on your assignment, the data may not be there. This means that you’d need to upload your data again.
Storing data persistently in Google Drive#
An alternative approach would be to save your data to Google Drive then mount your drive to your Colab session. Google Drive will provide persistent storage for your data, so you won’t need to upload data every time you plan to work with it. Your first step is to download the data for this assignment from TCU Online, then upload the data to your Google Drive account. Visit https://drive.google.com/ to view the Drive associated with your Google account. You’ll notice that you have a folder called “Colab notebooks” that stores all of the Colab notebooks you’ve created to this point.
If you want, you can upload your data directly to your Drive by clicking the New button then File upload. If you want to keep your data a bit more organized, you can first create a subfolder by clicking New > Folder, then uploading the adult_data.csv file to your subfolder.
Next, return to Colab. With the Files tab active, click the icon on the right side in the Files browser, “Mount Drive”. After you click this icon, you’ll see a code cell appear with the following code in it, along with a message telling you to run the cell:
from google.colab import drive
drive.mount('/content/drive')
A link will appear that will take you to the Google authentication/login screen. Choose your Google account and sign in if need be. You’ll get an authentication code, which you should copy then paste in the appropriate location in your Colab notebook. Press the Enter key after you’ve pasted your code, and allow the notebook to authenticate. Once authenticated, you should see a folder appear named drive in the Files browser. Navigate to the folder where you stored your adult_data.csv dataset, then right-click and choose “Copy path”.
In the code cell below, replace the value assigned to the data_path variable by pasting your specific path, then run the cell to load your data. My data is stored in a subfolder named class_data, but that is just for purposes of illustration.
import pandas as pd
data_path = "/content/drive/MyDrive/class_data/adult_data.csv"
df = pd.read_csv(data_path)
df.head()
Both the data upload and Google Drive-based workflows required specifying paths to your data. When you upload your data directly to Colab, the path is simply a string with the name of the dataset, as Colab places the file directly in the directory of your notebook. If you are using the Google Drive-based workflow, you need to specify the location of the file so your notebook can find it.
Now, let’s check to see how our data are formatted. We know from our preliminary inspection of the data that we have four columns; state, which contains the name of the state; then all_adults, male, and female, which contain the overweight/obesity rates for that state overall and by gender. state is an example of a nominal attribute, which refers to a descriptive property of the row; the other columns are ratio attributes, which are quantitative attributes in which zero refers to an absence of that quantity.
Recall from class as well the importance of knowing your column types. To check column types in pandas, use the dtypes attribute of the data frame.
df.dtypes
state object
all_adults float64
male float64
female float64
dtype: object
Our state column is stored as an object, which you can interpret as a string/text column; our other columns are float64, which means that they are numeric, allowing us to do mathematical operations.
Exploring data with descriptive statistics#
Now that we’ve read in our data, we’ll want to get a sense of some of its basic properties. You should recall from class that some of the most common descriptive statistics include measures of central tendency, which measure the “central point” of a distribution using different metrics, and measures of dispersion, which measure the “spread” of a distribution. The most common measure of central tendency used is the mean, which is also commonly termed the average of the distribution. The mean of a distribution is calculated by summing up all of the values in the distribution, and then dividing by the total number of values.
.mean() is a method built-in to pandas that allows you to calculate the mean for a column in a data frame - or alternatively, all columns in a data frame. Recall from class that columns can be accessed as attributes of the data frame or by index. In turn, the following calls are equivalent:
df.all_adults.mean()
0.6611509433962264
df["all_adults"].mean()
0.6611509433962264
Additionally, calling .mean() directly on the data frame will give back the mean for all of the data frame’s numeric columns.
Now you try! In the cells below, use the .median() method to determine the median value of the male column, which is the value at the 50 percent point of the distribution. Then, compare it with the median value of the female column.
# Run your code here!
There are many other built-in methods for getting descriptive statistics from your columns; for example, .min() will get you the minimum, .std() will get you the standard deviation, among many others. Commonly, however, you’ll want to get all of these statistics at once. pandas lets you do this with the .describe() method, which you can call on your data frame, or any selected columns, to return the most common descriptive statistics for those columns. For example:
df.describe()
| all_adults | male | female | |
|---|---|---|---|
| count | 53.000000 | 53.000000 | 53.000000 |
| mean | 0.661151 | 0.712019 | 0.608642 |
| std | 0.034600 | 0.028855 | 0.046197 |
| min | 0.558000 | 0.605000 | 0.513000 |
| 25% | 0.641000 | 0.698000 | 0.573000 |
| 50% | 0.665000 | 0.716000 | 0.616000 |
| 75% | 0.685000 | 0.729000 | 0.641000 |
| max | 0.733000 | 0.768000 | 0.704000 |
We get a nice summary here. In addition to the mean and median (the “50%” you see), pandas returns the count, standard deviation, min/max, and the values at the one-quarter and three-quarters points in the distribution, allowing us to determine the interquartile range.
While these numbers give us a general idea of the distribution of our data, tables of numbers are often not the most effective way to represent distributions. As such, we turn to visualization, which enables us to explore our data graphically.
Univariate visualization#
As we discussed in class, the principal library for data visualization in Python is matplotlib. matplotlib is an extraordinarily flexible package that allows Python users to create just about any type of visualization. However, it is sometimes criticized for being too “low-level” - that is, requiring a lot of code to accomplish simple tasks - and for having unattractive defaults.
While we will be working with matplotlib in this class, many of our interactions with the package will occur through built-in plotting functions in pandas as well as seaborn, a Python library for statistical visualization that is built on top of matplotlib, and is lauded for its attractive styling.
We’ll be using seaborn from this point forward in the notebook, so you’ll now want to import seaborn into your namespace. In this course, I’ll be using the standard import import seaborn as sns; seaborn’s creator Michael Waskom uses this in reference to the West Wing origins of the package’s name, as it is named after fictional White House deputy communications director Samuel Norman Seaborn, played by Rob Lowe.
To use seaborn styles, import the seaborn library then use the set_style function to choose a style. Available styles are "white", "whitegrid", "dark", "darkgrid", and "ticks".
import seaborn as sns
sns.set_style("darkgrid")
We are now ready to visualize our data! To get started, we’ll use a common type of visualization called a histogram. Histograms organize similar data values into bins, and then plot a series of bars whose heights represent the number of observations in each bin. Histograms are built in to pandas and in turn are available as data frame methods. Let’s draw a histogram of overweight/obesity rates. Run the code cell to view the plot.
df.all_adults.hist()
<Axes: >
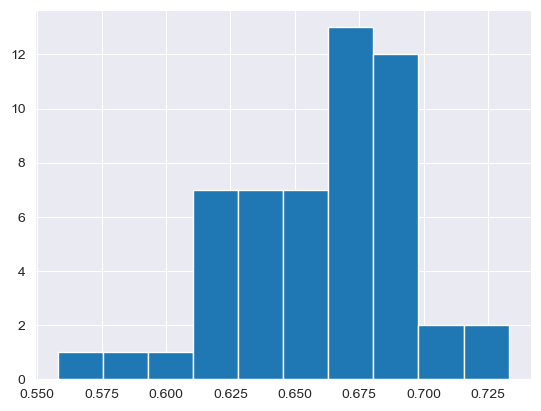
Histograms can also be build with seaborn functions, requiring different syntax. As opposed to the built-in pandas histogram, which treats the plot as a method belonging to the data frame object, seaborn functions are called with the data frame as an argument along with other arguments that control the styling of the plot.
sns.histplot(data = df, x = "all_adults", color = "black")
<Axes: xlabel='all_adults', ylabel='Count'>
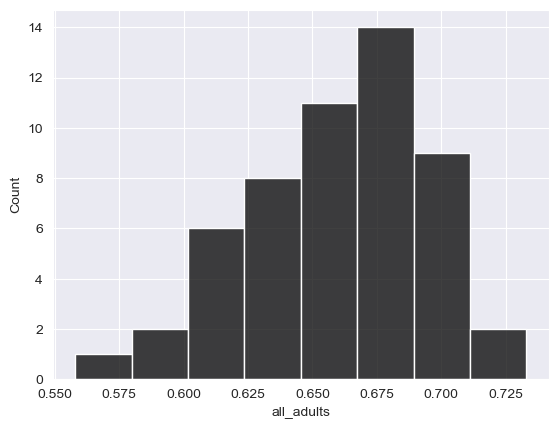
Spend some time trying to understand the graphs. Many chart types that we’ll explore in this class rely on the concept of the Cartesian coordinate system, which you may remember from grade school mathematics classes. Positions on the chart are defined by their x and y coordinates. The x-axis is the horizontal axis; in the above histogram, this represents the value in our all_adults column. The y-axis is the vertical axis, which in our histogram represents the number of observations in each bin. pandas defaults to 10 bins that are equal in width; seaborn calculates the number of bins from the size of the data, though this can be controlled with the bins parameter.
When interpreting a histogram, note the “shape” of the plot. Values tend to cluster around the right-hand side of the distribution, which is to be expected given that our mean and median are both around 66 percent; however, there are a few values in the tail of the distribution on the left-hand side that are noticeably lower.
Recall from class that a normal distribution refers to a distribution that is symmetrical around its mean. For example:
import numpy as np
np.random.seed(1983)
norm = pd.Series(np.random.randn(1000))
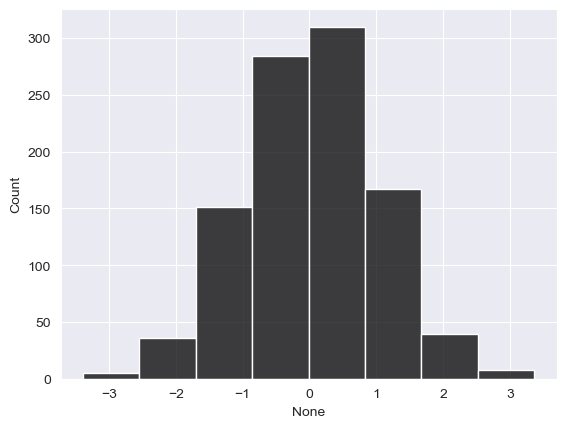
sns.histplot(x = norm, color = "black", bins = 8)
<Axes: xlabel='None', ylabel='Count'>
norm.describe()
count 1000.000000
mean 0.037654
std 0.999050
min -3.386319
25% -0.628936
50% 0.039946
75% 0.708724
max 3.359611
dtype: float64
You don’t need to understand everything I did in the above code yet; I used numpy to create a random sample of 1000 normally distributed observations with a mean of approximately 0 and a standard deviation of approximately 1. Notice how the histogram is reasonably symmetrical, and the mean and median are near-identical. In real data work - especially data work that involves observations of social phenomena- you’ll almost never come across perfectly normal distributions. A more detailed treatment of data distributions and probability should be left to your stats classes; however, I’ll mention a couple things you can look at.
In statistics, the “shape” of our distribution can be described by skew and kurtosis. Skew refers to the relative asymmetry of your distribution; negative skew means that the long tail of observations stretches to the left (the “negative” direction along the x-axis), and positive skew means that the long tail stretches to the right, the “positive” direction.
Skew can be quantified; we won’t get into the math behind it here, but it is available to you as a method in pandas:
df.all_adults.skew()
-0.5630178306448126
We see that our distribution has negative skew, as we observed from the plot; a normally-distributed sample would have a skew near 0.
norm.skew()
0.0029157841555743497
We can also examine the kurtosis of our distribution, which measures its “flatness” or “peakedness”. A distribution with a high “peak”, or many values clustered around the mean, is said to be leptokurtic; conversely, a distribution with a low peak and more even spread of values is platykurtic. pandas employs Fisher’s definition of kurtosis, in which a normal distribution has a kurtosis of 0, leptokurtic distributions have positive kurtosis values, and platykurtic distributions have negative values. For example:
df.all_adults.kurtosis()
0.4787907615464291
norm.kurtosis()
0.02974312878376395
We see that our data have a positive kurtosis, reflecting a higher “peak” than expected under normality.
Your histogram can also be customized; for example, as with other functions/methods in the Jupyter Notebook, use the help() function or type ? after typing the method (e.g. sns.histplot?) to see what parameters are available to you.
In the cell below, re-draw the histogram with 25 bins instead of 10 by supplying the argument to sns.histplot(), bins = 25. Take note of how the plot changes!
# Your code goes here!
You should notice that there are now gaps in your chart; as the histogram needs bins of equal width, there are some areas where no observations fall into the specified bins. As such, smoother representations of your data are sometimes preferable. A popular type of visualization that is related to the histogram is the kernel density plot, which represents the shape of your frequency distribution with a smooth curve. The mathematics behind the kernel density plot are beyond the scope of this course; however, the plot is still useful without knowing all of the math behind it.
seaborn includes a function, kdeplot, that lets us visualize our data with this kind of smooth curve.
sns.kdeplot(data = df, x = "all_adults")
<Axes: xlabel='all_adults', ylabel='Density'>
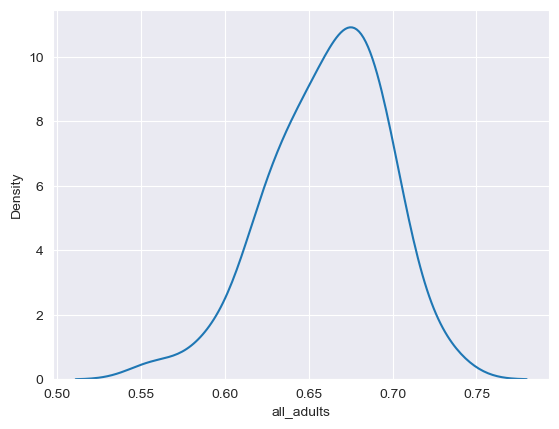
Be careful with the y-axis in kernel density plots; it looks similar to the histogram in this instance, but it represents something quantitatively different than the count as in the histogram that can be complicated to explain; the important thing for the purposes of our course here is the shape of the curve. As expected, we see a peak around 66-67 percent.
There are many options available to you to customize your density plots; for example, you can change the color of your data series, and fill the area under the curve:
sns.kdeplot(data = df, x = "all_adults", shade = True, color = "green")
/var/folders/qm/xbtsglmj2ss91z9fzpz8k6q8ylngb5/T/ipykernel_3703/3758865490.py:1: FutureWarning:
`shade` is now deprecated in favor of `fill`; setting `fill=True`.
This will become an error in seaborn v0.14.0; please update your code.
sns.kdeplot(data = df, x = "all_adults", shade = True, color = "green")
<Axes: xlabel='all_adults', ylabel='Density'>
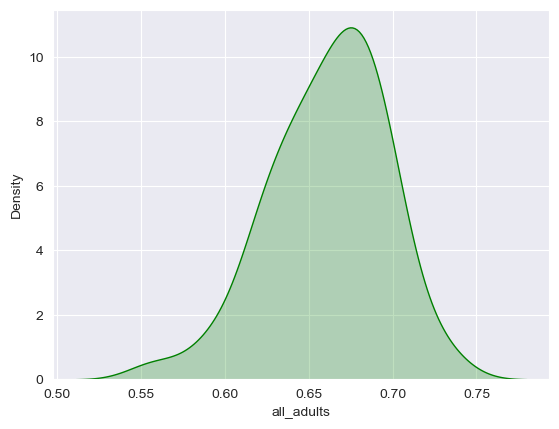
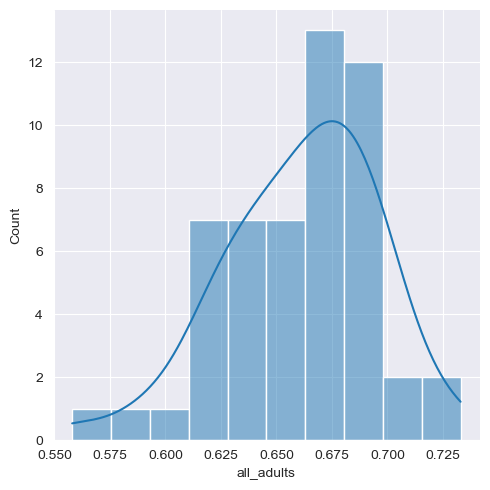
seaborn also has a built-in function called displot that will allow you to show a density curve and a histogram concurrently:
sns.displot(data = df, x = "all_adults", bins = 10, kde = True)
<seaborn.axisgrid.FacetGrid at 0x144ce9e10>
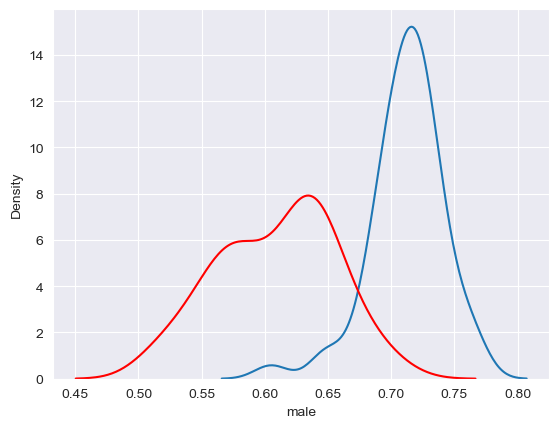
If desired, plots can also be superimposed on one another to make comparisons. For example, here we’ll overlay two density plots, one for male and one for female:
sns.kdeplot(data = df, x = "male")
sns.kdeplot(data = df, x = "female", color = "red")
<Axes: xlabel='male', ylabel='Density'>
An alternative way to visualize a frequency distribution is the box plot. As we discussed in class, box plots use three parallel lines to construct a box: one at the 25 percent point of the distribution, one at the median (50 percent point) of the distribution, and one at the 75 percent point of the distribution. “Whiskers” then extend to either the minimum/maximum values of the distribution or 150 percent (conventionally) of the 25/75 percent points, and observations beyond the whiskers are “outliers” represented with dots. seaborn allows us to draw box plots quite flexibly with its boxplot function:
sns.boxplot(data = df, x = "all_adults")
<Axes: xlabel='all_adults'>
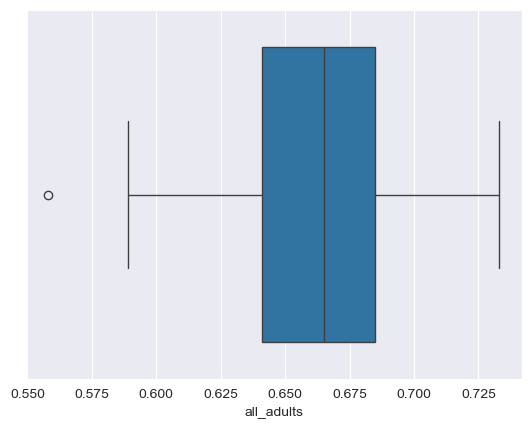
Notice how the dimensions of the box plot reflect the descriptive statistics we calculated earlier. Also, note the outliers on the left-hand side of the plot. The dot to the far left represents the District of Columbia, which has the lowest adult overweight/obesity rate in our sample. This makes sense, as DC is not really comparable to the 50 US states, given that it is a city in its entirety, and we know that dense cities tend to have lower adult overweight/obesity rates than suburbs and rural areas, which make up parts of all of our other observations. The state with the lowest overall rate is Colorado, which consistently ranks atop other states on health measures.
If you want, you can customize your box plot; for example, we can tell seaborn to orient it vertically by mapping the "all_adults" column to the y-axis:
sns.boxplot(data = df, y = "all_adults")
<Axes: ylabel='all_adults'>
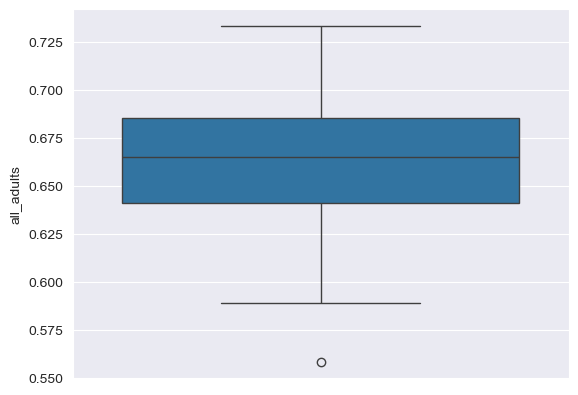
The final chart type I’ll introduce to you in this notebook is the violin plot. Violin plots are like combinations of box plots and density plots; they show the 25/50/75 percent values, as with box plots, but with density curves on either side of a central axis. Let’s take a look, again using seaborn:
sns.violinplot(data = df, x = "male")
<Axes: xlabel='male'>
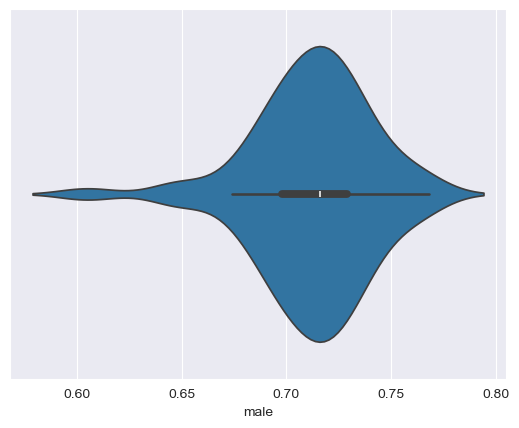
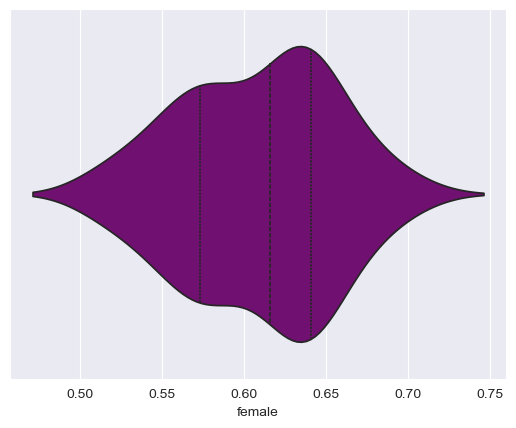
seaborn draws a miniature boxplot inside of symmetrical density curves representing the shape of the dataset. If you want, you can customize the visualization further; for example, I’ll tell seaborn to draw lines representing quartiles inside of the plot instead of the mini box plot, and change the color to purple:
sns.violinplot(data = df, x = "female", inner = "quartile", color = "purple")
<Axes: xlabel='female'>
Exercises#
Now it’s time to test what you’ve learned! In the following exercises, you’ll apply the techniques you’ve learned in this notebook to a new dataset from the Kaiser Family Foundation, which measures childhood overweight & obesity rates by state. The data file is named child_data.csv and is found on TCU Online. Read in the new dataset as a pandas DataFrame, and respond to the following questions:
Exercise 1: What are the mean and median values for childhood overweight/obesity rates for states in the US?
Exercise 2: What are the minimum and maximum values for childhood overweight/obesity rates? What is the range?
Exercise 3: Draw a histogram of childhood overweight/obesity rates. Do your data appear to be skewed in one direction or another?
Exercise 4: Draw a box plot of childhood overweight/obesity rates.
Exercise 5:: You pick: draw either a kernel density plot or a violin plot with your data. Change the color of the plot to orange, and shade the area beneath the density curve if you select a density plot.