In early 2023, the print copy of my book Analyzing US Census Data: Methods, Maps, and Models in R will be available for purchase. The response to the free online version of the book has been fantastic thus far. One question I commonly get asked, however, is “will you re-produce this for Python? I’d love to use this work but I don’t use R.”
I don’t have plans to replicate all of my R work in Python, but I did get the itch in the second half of 2022 to learn Python package development. The result is pygris, which is a port of the R tigris package but with some additional features.
To celebrate the publication of my book as well as the pygris package, I’m launching a blog series to illustrate how to reproduce some of my favorite examples from my book in Python. Each example will feature pygris. Follow along - I hope you find it useful!
I came into graduate school intending to be a qualitative researcher, but I really got excited about spatial data analysis (and changed my career trajectory) when I learned GeoDa, a GUI tool for exploratory spatial data analysis. The method in GeoDa that resonated with me the most was the local form of the Moran’s I, an example of a LISA (local indicators of spatial association) statistic.
LISAs are exploratory tools that help you make sense of spatial patterns in a dataset. They help surface preliminary answers to these questions:
Where are there concentrations of high attribute values in my spatial dataset?
Conversely, where can I find concentrations of low attribute values in my data?
Finally, are there any unexpected values in my dataset, given the characteristics of their neighbors? These “spatial outliers” can be above-average values surrounded by low values, or below-average values surrounded by high values.
This post will walk you through how to create an interactive LISA map of median age by Census tract from the 2017-2021 American Community Survey, similar to the example in Section 7.7.3 of my book. That section of my book covers more technical details about LISA if you are interested in reading further.
Let’s import the tracts() function to demonstrate how this works for the Minneapolis-St. Paul, Minnesota area. We’ll define a list of the seven core Twin Cities counties, and request Census tract boundaries for those counties with tracts(). pygris functions translate state names/abbreviations and county names internally to FIPS codes, so there is no need to look them up.
The argument year = 2021 gives back the 2021 version of the Census tract boundaries, which will be important as we’ll be matching to corresponding 2021 ACS data. Finally, the argument cache = True stores the downloaded shapefile in a local cache, which means that I won’t need to download it again from the Census website in future projects.
from pygris import tractstc_counties = ["Hennepin", "Ramsey", "Scott", "Carver", "Dakota", "Washington", "Anoka"]tc_tracts = tracts(state ="MN", county = tc_counties, year =2021, cache =True)tc_tracts.plot()
Using FIPS code '27' for input 'MN'
Using FIPS code '053' for input 'Hennepin'
Using FIPS code '123' for input 'Ramsey'
Using FIPS code '139' for input 'Scott'
Using FIPS code '019' for input 'Carver'
Using FIPS code '037' for input 'Dakota'
Using FIPS code '163' for input 'Washington'
Using FIPS code '003' for input 'Anoka'
<AxesSubplot:>
We’ll next need to grab data on median age and merge to the Census tract shapes. I don’t have plans to implement my R package tidycensus in Python; tidycensus is designed specifically for use within R’s tidyverse and Pythonic interfaces to the Census API like cenpy already exist. However, I’ve always admired Hannah Recht’s work on the R censusapi package, which can connect to all Census Bureau API endpoints. pygris includes a get_census() function inspired by censusapi that developers can use to build interfaces to the data they need.
Let’s use get_census() to get data on median age at the Census tract level for Minnesota, then merge to our Census tracts for additional analysis.
You can understand the arguments to get_census() as follows:
dataset is the dataset name on the Census API you are connecting to. Datasets can be found at https://api.census.gov/data.html in the “Dataset Name” column.
variables is a string (or list of strings) representing the variable IDs you want for a given dataset. For the 2021 5-year ACS, those variable IDs are found at https://api.census.gov/data/2021/acs/acs5/variables.html.
year is the year of your data (or end-year for a 5-year ACS sample); the Census API will refer to this as the “vintage” of the data.
params is a dict of query parameters to send to the API. Each endpoint will have its own parameters, so you’ll need to spend a little time with the Census API documentation to learn what you can use. In our case, we are requesting data for Census tracts in Minnesota. The built-in validate_state() function can be used here to convert 'MN' to an appropriate FIPS code.
guess_dtypes and return_geoid are convenience parameters that you’ll want to use judiciously. guess_dtypes tries to guess which columns to convert to numeric, and return_geoid tries to find columns to concatenate into a GEOID column that can be used for merging to Census shapes. These arguments won’t be appropriate for every API endpoint.
With our data in hand, we can do an inner merge and map the result:
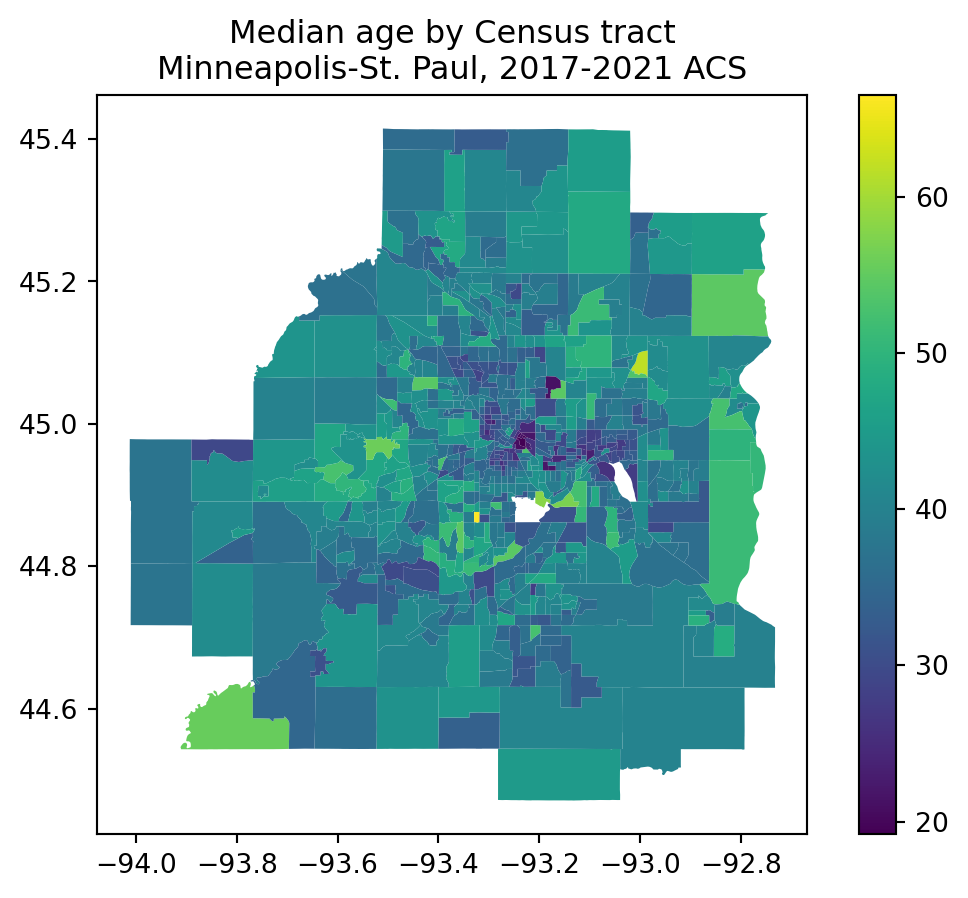
import matplotlib.pyplot as plttc_tract_age = tc_tracts.merge(mn_median_age, how ="inner", on ="GEOID")tc_tract_age.plot(column ="B01002_001E", legend =True)plt.title("Median age by Census tract\nMinneapolis-St. Paul, 2017-2021 ACS")
Text(0.5, 1.0, 'Median age by Census tract\nMinneapolis-St. Paul, 2017-2021 ACS')
Analyzing spatial clustering with PySAL
The PySAL family of Python packages is central to the work of anyone who needs to analyze spatial data in Python. The esda package makes the calculation of the local Moran’s I statistic remarkably smooth. We will generate a Queen’s case spatial weights object (see my book for more technical details) to represent relationships between Census tracts and their neighbors, then call the Moran_Local() function to calculate the LISA statistics.
Using this information, we can identify “significant” and “non-significant” clusters and generate some more informative labels.
import numpy as np# We can extract the LISA quadrant along with the p-value from the lisa objecttc_clean['quadrant'] = m.qtc_clean['p_sim'] = m.p_sim# Convert all non-significant quadrants to zerotc_clean['quadrant'] = np.where(tc_clean['p_sim'] >0.05, 0, tc_clean['quadrant'])# Get more informative descriptionstc_clean['quadrant'] = tc_clean['quadrant'].replace( to_replace = {0: "Not significant",1: "High-high",2: "Low-high",3: "Low-low",4: "High-low" })tc_clean.head()
GEOID
B01002_001E
geometry
quadrant
p_sim
0
27053103700
29.3
POLYGON ((-93.25825 44.98358, -93.25790 44.983...
Not significant
0.070
1
27053104100
28.2
POLYGON ((-93.31847 44.98174, -93.31847 44.983...
Low-low
0.043
2
27053104400
32.4
POLYGON ((-93.28158 44.97790, -93.28153 44.978...
Not significant
0.228
3
27053105100
44.6
POLYGON ((-93.32873 44.96012, -93.32873 44.960...
Not significant
0.127
4
27053105400
33.2
POLYGON ((-93.26972 44.96807, -93.26926 44.969...
Not significant
0.310
Building an interactive LISA map
We now have all the information necessary to map LISA clusters. I’m going to show a workflow that differs slightly from typical LISA maps like the one illustrated in my book. One disadvantage of static LISA maps is that they assume an analyst has familiarity with the region under study. Without this familiarity, it can be difficult to determine exactly which locations are represented by different cluster types.
Enter the .explore() GeoDataFrame method in GeoPandas. .explore() is an interface to Leaflet.js through Folium. Simply calling .explore() on a GeoDataFrame gets you started interactively exploring your spatial data; however, the method itself is a fairly full-featured interactive mapping engine.
With a little customization, we can build out an informative interactive map showing our LISA analysis of median age by Census tract in the Twin Cities. Here’s how we do it:
We choose "quadrant" as the column to visualize, and pass a list of colors to cmap to align with the typical color scheme used for LISA mapping (with some small modifications to improve visibility).
legend = True adds an informative legend, and a muted grey basemap is selected with tiles.
The various _kwds parameters are quite powerful, as this is how you will do more fine-grained customization of your map. We’ll reduce the line weight of our polygons to 0.5, and importantly do some customization of the popup to change the column names to informative aliases. Click on a Census tract to see what you get!
Make this Notebook Trusted to load map: File -> Trust Notebook
Our analytical result shows that younger areas tend to be found nearer to the Minneapolis / St. Paul urban cores, and older areas cluster in the western, southern, and northeastern suburbs. Spatial outliers are scattered throughout the region, and the map’s interactivity allows us to zoom in and click to understand these outliers in greater detail.
Try out this workflow for yourself, and follow along here for more of my favorite examples from Analyzing US Census Data translated to Python over the next few months.