9 Introduction to Census microdata
The previous chapters in this book focus on aggregate-level analysis of US Census Bureau data. However, such analyses are limited to the pre-tabulated estimates provided by the Census Bureau. While these estimates are voluminous, they may not include the level of detail required by researchers, and they are limited to analyses appropriate for aggregate-level data. In turn, many researchers turn to Census microdata, which are anonymized individual-level Census records, to help answer demographic questions. In 2020, tidycensus added support for American Community Survey microdata along with a series of tools to assist with analysis of these datasets. The next two chapters provide an overview of this functionality in tidycensus and help users get started analyzing and modeling ACS microdata appropriately.
9.1 What is “microdata?”
Microdata refer to individual-level data made available to researchers. In many cases, microdata reflect responses to surveys that are de-identified and anonymized, then prepared in datasets that include rich detail about survey responses. US Census microdata are available for both the decennial Census and the American Community Survey; these datasets, named the Public Use Microdata Series (PUMS), allow for detailed cross-tabulations not available in aggregated data.
The ACS PUMS is available, like the aggregate data, in both 1-year and 5-year versions. The 1-year PUMS covers about 1 percent of the US population, whereas the 5-year PUMS covers about 5 percent; this means that microdata represent a smaller subset of the US population than the regular ACS. Public use microdata downloads available in bulk from the Census FTP server or from data.census.gov’s MDAT tool.
The Census Bureau also operates a network of Federal Statistical Research Data Centers (FSRDCs) around the country that grant access to microdata with larger sample sizes and greater demographic detail. To work at one of these centers, researchers must get special government clearance and have an approved proposal with the US Census Bureau. This and the following chapter focus on the public use microdata product, which is much more accessible to researchers and analysts.
9.1.1 Microdata resources: IPUMS
One of the most popular and comprehensive repositories for research microdata is the University of Minnesota’s IPUMS project (Ruggles et al. 2020). IPUMS includes Decennial US Census and ACS microdata (IPUMS USA), microdata from the Current Population Survey (IPUMS CPS), and over 100 countries around the world (IPUMS International).
Figure 9.1: IPUMS home page
IPUMS releases microdata that are harmonized, which means that changing variable definitions over time are aligned by the IPUMS team to allow for coherent longitudinal analysis. Using IPUMS requires signing up for an account and making a request through their web interface, then downloading a data extract; an API is under development. IPUMS data products will be covered in more detail in Chapter 11, which will also introduce the ipumsr R package (Ellis and Burk 2020) for working with IPUMS data in R.
9.1.2 Microdata and the Census API
The migration of US Census data from American FactFinder to the data.census.gov tool integrated the Census Bureau’s data download interface with its API. The Census Bureau’s MDAT tool allows for flat file downloads of microdata along with API queries for microdata, marking the first time that microdata are available via the API.
Figure 9.2: MDAT tool from data.census.gov
This means that microdata can be accessed with httr::GET() requests in R, but also made ACS microdata accessible to tidycensus. In 2020, tidycensus released a range of features to support ACS microdata for R users; this functionality is covered in the remainder of this chapter.
9.2 Using microdata in tidycensus
American Community Survey microdata are available in tidycensus by using the get_pums() function, which communicates with the Census API much like other tidycensus functions and returns PUMS data. Given the unique properties of Census microdata and the different structure of individual-level records as opposed to aggregate data, the data returned by get_pums() differs from other tidycensus functions. This section covers the basics of requesting microdata extracts with tidycensus.
9.2.1 Basic usage of get_pums()
get_pums() requires specifying one or more variables and the state for which you’d like to request data. For national-level analyses, state = 'all' can get data for the entire USA by iterating over all US states, but the data can take some time to download depending on the user’s internet connection. The get_pums() function defaults to the 5-year ACS with survey = "acs5"; 1-year ACS data is available with survey = "acs1". At the time of this writing, data are available from 2006 through 2019 for the 1-year ACS and 2005-2009 through 2016-2020 for the 5-year ACS.
Let’s take a look at a first example using get_pums() to request microdata for Wyoming from the 1-year 2019 ACS with information on sex, age (AGEP), and household type (HHT).
library(tidycensus)
wy_pums <- get_pums(
variables = c("SEX", "AGEP", "HHT"),
state = "WY",
survey = "acs1",
year = 2019
)| SERIALNO | SPORDER | WGTP | PWGTP | AGEP | ST | HHT | SEX |
|---|---|---|---|---|---|---|---|
| 2019GQ0000335 | 1 | 0 | 206 | 17 | 56 | b | 2 |
| 2019GQ0000958 | 1 | 0 | 50 | 37 | 56 | b | 1 |
| 2019GQ0009156 | 1 | 0 | 33 | 75 | 56 | b | 2 |
| 2019GQ0012426 | 1 | 0 | 23 | 21 | 56 | b | 2 |
| 2019GQ0015243 | 1 | 0 | 209 | 94 | 56 | b | 1 |
| 2019GQ0018773 | 1 | 0 | 273 | 26 | 56 | b | 1 |
| 2019GQ0019978 | 1 | 0 | 6 | 16 | 56 | b | 1 |
| 2019GQ0022931 | 1 | 0 | 67 | 18 | 56 | b | 2 |
| 2019GQ0032421 | 1 | 0 | 113 | 94 | 56 | b | 2 |
| 2019GQ0033045 | 1 | 0 | 10 | 44 | 56 | b | 1 |
The function returns just under 6,000 rows of data with our requested variables in the columns. However, a few other variables are also returned that we did not request; these default variables are covered below.
9.2.2 Understanding default data from get_pums()
get_pums() returns some technical variables by default without the user needing to request them specifically. These technical variables are essential for uniquely identifying observations in the dataset and eventually performing any analysis and modeling. These default technical variables include:
SERIALNO: a serial number that uniquely identifies households in the sample;SPORDER: the order of the person in the household, which when combined withSERIALNOuniquely identifies a person;WGTP: the household weight;PWGTP: the person weight;ST: the state FIPS code.
Given that PUMS data are a sample of the US population, the weights columns must be used for analysis. In general terms, we can interpret the weights as “the number of observations in the general population represented by this particular row in the dataset.” In turn, a row with a PWGTP value of 50 represents about 50 people in Wyoming with the same demographic characteristics of the “person” in that row.
Inferences about population characteristics can be made by summing over the weights columns. For example, let’s say we want to get an estimate of the number of people in Wyoming who are 50 years old in 2019, and compare this with the total population in Wyoming. We can filter the dataset for rows that match the condition AGEP == 50, then sum over the PWGTP column.
## [1] 578759## [1] 4756Our data suggest that of the 578,759 people in Wyoming in 2019, about 4,756 were 50 years old. Of course, this estimate will be subject to a margin of error; the topic of error calculations from PUMS data will be covered in the next chapter.
It is important to note that get_pums() returns two separate weights columns: one for households and one for persons. Let’s take a look at a single household in the Wyoming dataset to examine this further.
wy_hh_example <- filter(wy_pums, SERIALNO == "2019HU0456721")
wy_hh_example## # A tibble: 4 × 8
## SERIALNO SPORDER WGTP PWGTP AGEP ST HHT SEX
## <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <chr>
## 1 2019HU0456721 1 146 146 40 56 1 2
## 2 2019HU0456721 2 146 132 45 56 1 1
## 3 2019HU0456721 3 146 94 8 56 1 2
## 4 2019HU0456721 4 146 154 5 56 1 1This household includes a woman aged 40, a man aged 45, and two children: a girl aged 8 and a boy aged 5. The HHT value is 1, which tells us that this is a married-couple household. Notably, the household weight value, WGTP, is identical for all household members, whereas the person weight value, PWGTP, is not.
Microdata retrieved from the Census API are a hybrid of both household-level data and person-level data, which means that analysts need to take care to use appropriate weights and filters for household-level or person-level analyses. For example, to determine the number of households in Wyoming, the dataset should be filtered to records where the SPORDER column is equal to 1 then summed over the WGTP column. Persons living in group quarters will be excluded automatically as they have a household weight of 0.
## [1] 233126Housing unit rather than simply household-level analyses introduce an additional level of complexity, as housing units can be both occupied and vacant. Vacant housing units are returned in a different format from the Census API which makes them a special case in tidycensus. To return vacant housing units along with person and household records, use the argument return_vacant = TRUE.
wy_with_vacant <- get_pums(
variables = c("SEX", "AGEP", "HHT"),
state = "WY",
survey = "acs1",
year = 2019,
return_vacant = TRUE
) %>%
arrange(VACS)| SERIALNO | SPORDER | WGTP | PWGTP | AGEP | ST | VACS | HHT | SEX |
|---|---|---|---|---|---|---|---|---|
| 2019HU0138328 | NA | 81 | NA | NA | 56 | 1 | b | NA |
| 2019HU0176734 | NA | 408 | NA | NA | 56 | 1 | b | NA |
| 2019HU0181695 | NA | 47 | NA | NA | 56 | 1 | b | NA |
| 2019HU0322496 | NA | 71 | NA | NA | 56 | 1 | b | NA |
| 2019HU0387947 | NA | 197 | NA | NA | 56 | 1 | b | NA |
| 2019HU0542474 | NA | 414 | NA | NA | 56 | 1 | b | NA |
| 2019HU0561251 | NA | 117 | NA | NA | 56 | 1 | b | NA |
| 2019HU0577606 | NA | 188 | NA | NA | 56 | 1 | b | NA |
| 2019HU0614046 | NA | 162 | NA | NA | 56 | 1 | b | NA |
| 2019HU0669741 | NA | 239 | NA | NA | 56 | 1 | b | NA |
Vacant housing units are included in the dataset, but as they do not have person-level characteristics (due to their lack of occupancy) all person-level variables like age and sex have values of NA.
9.3 Working with PUMS variables
While the ACS PUMS dataset does not include tens of thousands of variables choices like its aggregate counterpart, it nonetheless includes variables and variable codes that can be difficult to understand without a data dictionary. In the Wyoming example above, only interpretation of the AGEP column for age is straightforward. HHT, for household type, and SEX, for sex, are coded as integers represented as character strings. To help users understand the meanings of these codes, tidycensus includes a built-in dataset, pums_variables, that can be viewed, filtered, and browsed.
9.3.1 Variables available in the ACS PUMS
As with the data dictionaries for the decennial Census and aggregate ACS obtained with load_variables(), it is advisable to browse the PUMS data dictionary, pums_variables, with the View() function in RStudio.
View(pums_variables)pums_variables is a long-form dataset that organizes specific value codes by variable so you know what you can get with get_pums(). You’ll use information in the var_code column to fetch variables, but pay close attention to the var_label, val_min, val_max, val_label, and data_type columns. These columns should be interpreted as follows:
-
var_codegives you the variable codes that should be supplied to thevariablesparameter (as a character vector) inget_pums(). These variables will be represented in the columns of your output dataset. -
var_labelis a more informative description of the variable’s topic. -
data_typeis one of"chr", for categorical variables that will be returned as R character strings, or"num", for variables that will be returned as numeric. -
val_minandval_maxprovide information about the meaning of the data values. For categorical variables, these two columns will be the same; for numeric variables, they will give you the possible range of data values. -
val_labelcontains the value labels, which are particularly important for understanding the content of categorical variables.
9.3.2 Recoding PUMS variables
A typical tidycensus workflow covered earlier in this book involves browsing the appropriate data dictionary, choosing variable IDs, and using those IDs in your scripts and workflows. Analysts will likely follow this same process with get_pums(), but can also use the argument recode = TRUE to return additional contextual information with the requested data. recode = TRUE instructs get_pums() to append recoded columns to your returned dataset based on information available in pums_variables. Let’s take a look at the Wyoming example with recode = TRUE.
wy_pums_recoded <- get_pums(
variables = c("SEX", "AGEP", "HHT"),
state = "WY",
survey = "acs1",
year = 2019,
recode = TRUE
)| SERIALNO | SPORDER | WGTP | PWGTP | AGEP | ST | HHT | SEX | ST_label | HHT_label | SEX_label |
|---|---|---|---|---|---|---|---|---|---|---|
| 2019GQ0000335 | 1 | 0 | 206 | 17 | 56 | b | 2 | Wyoming/WY | N/A (GQ/vacant) | Female |
| 2019GQ0000958 | 1 | 0 | 50 | 37 | 56 | b | 1 | Wyoming/WY | N/A (GQ/vacant) | Male |
| 2019GQ0009156 | 1 | 0 | 33 | 75 | 56 | b | 2 | Wyoming/WY | N/A (GQ/vacant) | Female |
| 2019GQ0012426 | 1 | 0 | 23 | 21 | 56 | b | 2 | Wyoming/WY | N/A (GQ/vacant) | Female |
| 2019GQ0015243 | 1 | 0 | 209 | 94 | 56 | b | 1 | Wyoming/WY | N/A (GQ/vacant) | Male |
| 2019GQ0018773 | 1 | 0 | 273 | 26 | 56 | b | 1 | Wyoming/WY | N/A (GQ/vacant) | Male |
| 2019GQ0019978 | 1 | 0 | 6 | 16 | 56 | b | 1 | Wyoming/WY | N/A (GQ/vacant) | Male |
| 2019GQ0022931 | 1 | 0 | 67 | 18 | 56 | b | 2 | Wyoming/WY | N/A (GQ/vacant) | Female |
| 2019GQ0032421 | 1 | 0 | 113 | 94 | 56 | b | 2 | Wyoming/WY | N/A (GQ/vacant) | Female |
| 2019GQ0033045 | 1 | 0 | 10 | 44 | 56 | b | 1 | Wyoming/WY | N/A (GQ/vacant) | Male |
Note that the dataset returns three new columns: ST_label, HHT_label, and SEX_label which include longer and more informative descriptions of the value labels. These columns are returned as ordered factors that preserve the original ordering of the columns independent of their alphabetical order. Numeric columns like AGEP are not recoded as the data values reflect numbers, not a categorical label.
9.3.3 Using variables filters
PUMS datasets, especially those from the 5-year ACS, can get quite large. Even users with speedy internet connections will need to be patient when downloading what could be millions of records from the Census API and potentially risk internet hiccups. When only subsets of data are required for an analysis, the variables_filter argument can return a subset of data from the API, reducing long download times.
The variables_filter argument should be supplied as a named list where variable names (which can be quoted or unquoted) are paired with a data value or vector of data values to be requested from the API. The “filter” works by passing a special query to the Census API which will only return a subset of data, meaning that the entire dataset does not need to be first downloaded then filtered on the R side. This leads to substantial time savings for targeted queries.
In the example below, the Wyoming request is modified with variables_filter to return only women (SEX = 2) between the ages of 30 and 49, but this time from the 5-year ACS PUMS.
wy_pums_filtered <- get_pums(
variables = c("SEX", "AGEP", "HHT"),
state = "WY",
survey = "acs5",
variables_filter = list(
SEX = 2,
AGEP = 30:49
),
year = 2019
)| SERIALNO | SPORDER | WGTP | PWGTP | AGEP | ST | HHT | SEX |
|---|---|---|---|---|---|---|---|
| 2015000004982 | 1 | 28 | 29 | 39 | 56 | 1 | 2 |
| 2015000014993 | 1 | 18 | 19 | 44 | 56 | 3 | 2 |
| 2015000016130 | 1 | 22 | 23 | 48 | 56 | 1 | 2 |
| 2015000025094 | 1 | 16 | 16 | 31 | 56 | 1 | 2 |
| 2015000032486 | 1 | 65 | 65 | 36 | 56 | 3 | 2 |
| 2015000044674 | 1 | 14 | 13 | 40 | 56 | 1 | 2 |
| 2015000045979 | 1 | 18 | 17 | 49 | 56 | 3 | 2 |
| 2015000052006 | 2 | 13 | 14 | 37 | 56 | 1 | 2 |
| 2015000053688 | 1 | 21 | 22 | 40 | 56 | 1 | 2 |
| 2015000067452 | 3 | 11 | 10 | 43 | 56 | 2 | 2 |
The returned dataset reflects the filter request, with data values in the AGEP column only ranging between 30 and 49 and the SEX column only including 2, for female.
9.4 Public Use Microdata Areas (PUMAs)
One of the steps the Census Bureau takes to preserve anonymity in the PUMS datasets is limiting the geographical detail in the data. Granular Census geographical information like the Census tract or block group of residence for individuals in the PUMS samples are not available. That said, some geographical information is available in the PUMS samples in the form of the Public Use Microdata Area, or PUMA.
9.4.1 What is a PUMA?
Public Use Microdata Areas (PUMAs) are the smallest available geographies at which records are identifiable in the PUMS datasets. PUMAs are redrawn with each decennial US Census, and typically are home to between 100,000 - 200,000 people when drawn, although some may be much larger by the end of a Census cycle. In large cities, a PUMA will represent a collection of nearby neighborhoods; in rural areas, it might represent several counties across a large area of a state.
At the time of this writing, PUMA geographies correspond to the 2010 Census definitions, even. While PUMAs are redrawn with each decennial US Census, their release lags the decennial Census by a couple of years. To determine appropriate PUMA geographies, the Census Bureau consults with State Data Centers (SDCs) and incorporates their suggested revisions to these geographies. For 2020 PUMAs, this process takes place through the 2021 calendar year. This means that the updated PUMA geographies, and their incorporation into PUMS datasets, are planned for public release in the summer of 2022. For more information, visit https://www.census.gov/programs-surveys/geography/guidance/geo-areas/pumas/2020pumas.html.
PUMA geographies can be obtained and reviewed with the pumas() function in the tigris package. Let’s take a look at PUMA geographies for the state of Wyoming:
library(tigris)
options(tigris_use_cache = TRUE)
wy_pumas <- pumas(state = "WY", cb = TRUE, year = 2019)
ggplot(wy_pumas) +
geom_sf() +
theme_void()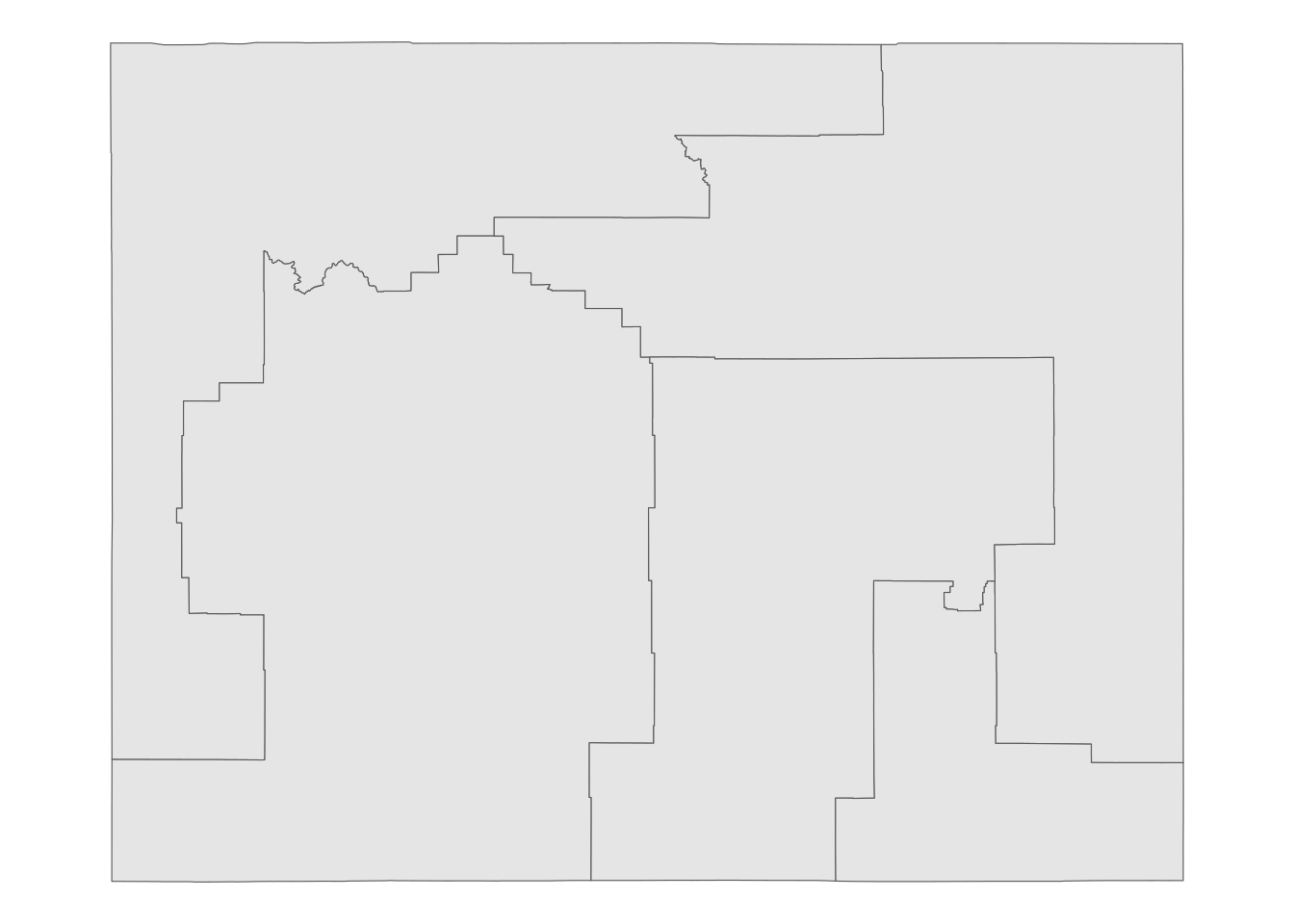
Figure 9.3: Basic map of PUMAs in Wyoming
There are five PUMAs in Wyoming, largely covering large rural areas of the state, although the smallest PUMA by area covers the more urban southeast corner of the state. The returned object includes a NAME10 column with an informative description of the PUMAs:
wy_pumas$NAME10## [1] "Sheridan, Park, Teton, Lincoln & Big Horn Counties"
## [2] "Sweetwater, Fremont, Uinta, Sublette & Hot Springs Counties--Wind River Reservation"
## [3] "Campbell, Goshen, Platte, Johnson, Washakie, Weston, Crook & Niobrara Counties"
## [4] "Natrona, Carbon & Converse Counties"
## [5] "Laramie & Albany Counties"In a denser urban area, PUMAs will reflect subsections of major cities and are drawn in attempts to reflect meaningful local areas. In New York City, for example, PUMAs are drawn to align with recognized community districts in the city.
nyc_pumas <- pumas(state = "NY", cb = TRUE, year = 2019) %>%
filter(str_detect(NAME10, "NYC"))
ggplot(nyc_pumas) +
geom_sf() +
theme_void()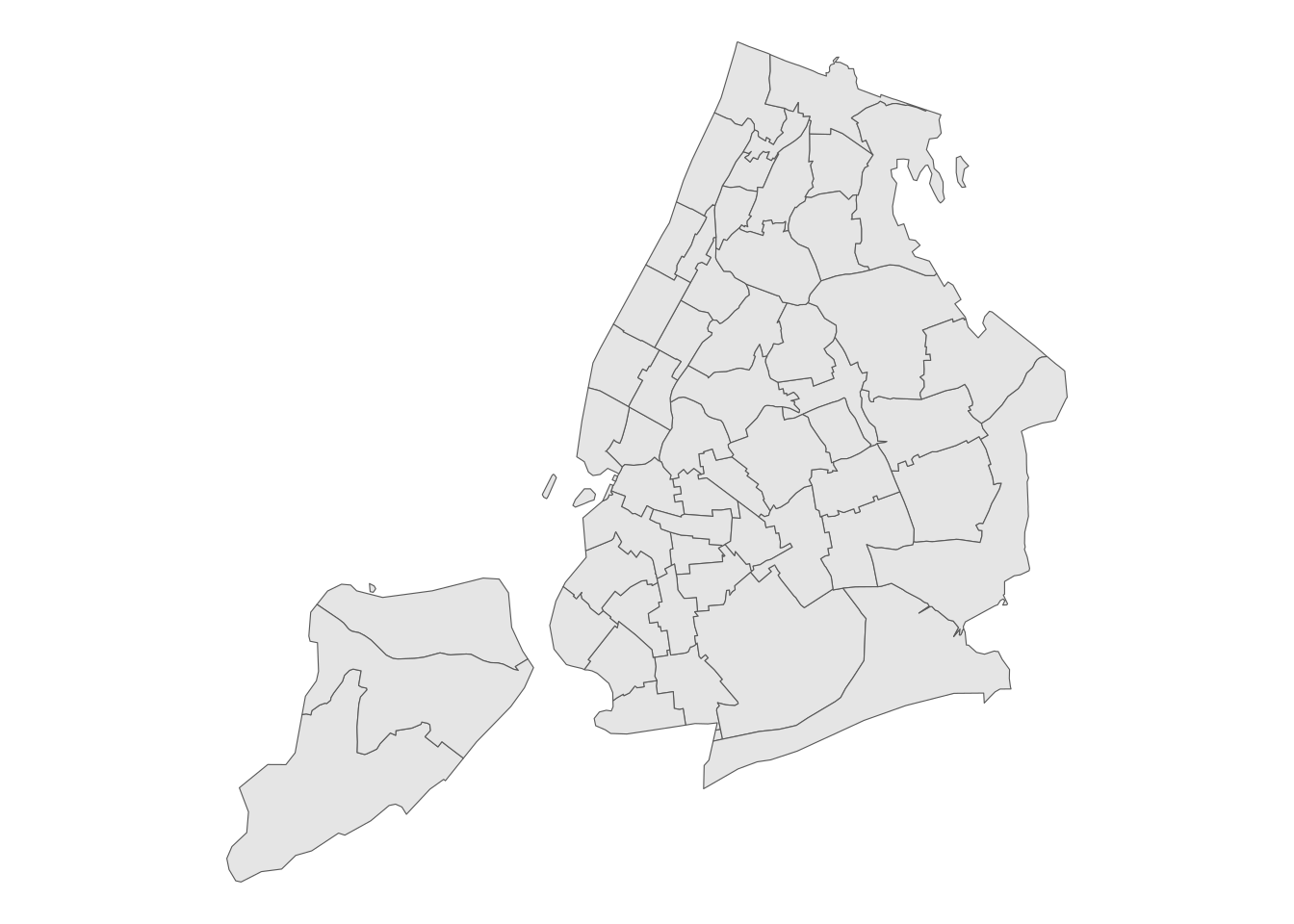
Figure 9.4: Map of PUMAs in New York City
The names of NYC’s PUMAs themselves reflect the community districts in the geographic data returned by tigris.
nyc_pumas$NAME10[1:5]## [1] "NYC-Manhattan Community District 11--East Harlem"
## [2] "NYC-Manhattan Community District 8--Upper East Side"
## [3] "NYC-Bronx Community District 11--Pelham Parkway, Morris Park & Laconia"
## [4] "NYC-Manhattan Community District 9--Hamilton Heights, Manhattanville & West Harlem"
## [5] "NYC-Brooklyn Community District 12--Borough Park, Kensington & Ocean Parkway"9.4.2 Working with PUMAs in PUMS data
PUMA information is available with the variable code PUMA in get_pums(). Use PUMA like any other variable to return information about the PUMA of residence for the individual records.
wy_age_by_puma <- get_pums(
variables = c("PUMA", "AGEP"),
state = "WY",
survey = "acs5",
year = 2019
)| SERIALNO | SPORDER | WGTP | PWGTP | AGEP | PUMA | ST |
|---|---|---|---|---|---|---|
| 2015000001990 | 1 | 27 | 26 | 67 | 00300 | 56 |
| 2015000006752 | 1 | 5 | 5 | 86 | 00100 | 56 |
| 2015000006752 | 2 | 5 | 6 | 83 | 00100 | 56 |
| 2015000006847 | 1 | 29 | 29 | 61 | 00300 | 56 |
| 2015000007045 | 1 | 23 | 23 | 62 | 00300 | 56 |
| 2015000007045 | 2 | 23 | 19 | 66 | 00300 | 56 |
| 2015000007045 | 3 | 23 | 34 | 35 | 00300 | 56 |
| 2015000007382 | 1 | 17 | 17 | 33 | 00500 | 56 |
| 2015000010448 | 1 | 9 | 9 | 69 | 00100 | 56 |
| 2015000010448 | 2 | 9 | 9 | 77 | 00100 | 56 |
PUMA IDs are replicated across states, so the PUMA column should be combined with the ST column to uniquely identify PUMAs when performing multi-state analyses.
The puma argument in get_pums() can also be used to obtain data for a specific PUMA or multiple PUMAs. Like the variables_filter parameter, puma uses a query on the API side to reduce long download times for users only interested in a geographical subset of data.
wy_puma_subset <- get_pums(
variables = "AGEP",
state = "WY",
survey = "acs5",
puma = "00500",
year = 2019
)| SERIALNO | SPORDER | WGTP | PWGTP | AGEP | PUMA | ST |
|---|---|---|---|---|---|---|
| 2015000010667 | 1 | 11 | 12 | 38 | 00500 | 56 |
| 2015000010667 | 2 | 11 | 14 | 36 | 00500 | 56 |
| 2015000010667 | 3 | 11 | 14 | 5 | 00500 | 56 |
| 2015000018572 | 1 | 8 | 8 | 80 | 00500 | 56 |
| 2015000040346 | 1 | 24 | 23 | 54 | 00500 | 56 |
| 2015000040346 | 2 | 24 | 31 | 55 | 00500 | 56 |
| 2015000042859 | 1 | 7 | 8 | 60 | 00500 | 56 |
| 2015000042859 | 2 | 7 | 4 | 53 | 00500 | 56 |
| 2015000047414 | 1 | 17 | 16 | 60 | 00500 | 56 |
| 2015000047414 | 2 | 17 | 35 | 72 | 00500 | 56 |
For multi-state geographical queries, the puma argument must be adapted slightly due to the aforementioned possibility that PUMA IDs will be replicated across states. To perform a multi-state query by PUMA, specify state = "multiple" and pass a named vector of state/PUMA pairs to the puma parameter.
twostate_puma_subset <- get_pums(
variables = "AGEP",
state = "multiple",
survey = "acs5",
puma = c("WY" = "00500", "UT" = "05001"),
year = 2019
)| SERIALNO | SPORDER | WGTP | PWGTP | AGEP | PUMA | ST |
|---|---|---|---|---|---|---|
| 2015000000486 | 1 | 18 | 18 | 29 | 05001 | 49 |
| 2015000000486 | 2 | 18 | 13 | 30 | 05001 | 49 |
| 2015000000486 | 3 | 18 | 13 | 4 | 05001 | 49 |
| 2015000000486 | 4 | 18 | 12 | 1 | 05001 | 49 |
| 2015000000486 | 5 | 18 | 13 | 0 | 05001 | 49 |
| 2015000001125 | 1 | 20 | 20 | 50 | 05001 | 49 |
| 2015000001125 | 2 | 20 | 19 | 52 | 05001 | 49 |
| 2015000001125 | 3 | 20 | 10 | 16 | 05001 | 49 |
| 2015000007778 | 1 | 4 | 3 | 27 | 05001 | 49 |
| 2015000008887 | 1 | 3 | 3 | 32 | 00500 | 56 |
The returned data include neighboring areas in Wyoming and Utah.
9.5 Exercises
Try requesting PUMS data using
get_pums()yourselves, but for a state other than Wyoming.Use the
pums_variablesdataset to browse the available variables in the PUMS. Create a custom query withget_pums()to request data for variables other than those we’ve used in the above examples.