6 Mapping Census data with R
Data from the United States Census Bureau are commonly visualized using maps, given that Census and ACS data are aggregated to enumeration units. This chapter will cover the process of map-making using the tidycensus R package. Notably, tidycensus enables R users to download simple feature geometry for common geographies, linking demographic information with their geographic locations in a dataset. In turn, this data model facilitates the creation of both static and interactive demographic maps.
In this chapter, readers will learn how to use the geometry parameter in tidycensus functions to download geographic data along with demographic data from the US Census Bureau. The chapter will then cover how to make static maps of Census demographic data using the popular ggplot2 and tmap visualization packages. The closing parts of the chapter will then turn to interactive mapping, with a focus on the mapview and Leaflet R packages for interactive cartographic visualization.
6.1 Using geometry in tidycensus
As covered in the previous chapter, Census geographies are available from the tigris R package as simple features objects, using the data model from the sf R package. tidycensus wraps several common geographic data functions in the tigris package to allow R users to return simple feature geometry pre-linked to downloaded demographic data with a single function call. The key argument to accomplish this is geometry = TRUE, which is available in the core data download functions in tidycensus, get_acs(), get_decennial(), and get_estimates().
Traditionally, getting “spatial” Census data requires a tedious multi-step process that can involve several software platforms. These steps include:
Fetching shapefiles from the Census website;
Downloading a CSV of data, then cleaning and formatting it;
Loading geometries and data into your desktop GIS of choice;
Aligning key fields in your desktop GIS and joining your data.
A major motivation for developing tidycensus was my frustration with having to go through this process over and over again before making a simple map of Census data. geometry = TRUE combines the automated data download functionality of tidycensus and tigris to allow R users to bypass this process entirely. The following example illustrates the use of the geometry = TRUE argument, fetching information on median household income for Census tracts in the District of Columbia. As discussed in the previous chapter, the option tigris_use_cache = TRUE is used to cache the downloaded geographic data on the user’s computer.
library(tidycensus)
options(tigris_use_cache = TRUE)
dc_income <- get_acs(
geography = "tract",
variables = "B19013_001",
state = "DC",
year = 2020,
geometry = TRUE
)
dc_income## Simple feature collection with 206 features and 5 fields
## Geometry type: POLYGON
## Dimension: XY
## Bounding box: xmin: -77.11976 ymin: 38.79165 xmax: -76.9094 ymax: 38.99511
## Geodetic CRS: NAD83
## First 10 features:
## GEOID NAME
## 1 11001005003 Census Tract 50.03, District of Columbia, District of Columbia
## 2 11001002503 Census Tract 25.03, District of Columbia, District of Columbia
## 3 11001006801 Census Tract 68.01, District of Columbia, District of Columbia
## 4 11001009802 Census Tract 98.02, District of Columbia, District of Columbia
## 5 11001008904 Census Tract 89.04, District of Columbia, District of Columbia
## 6 11001003301 Census Tract 33.01, District of Columbia, District of Columbia
## 7 11001000704 Census Tract 7.04, District of Columbia, District of Columbia
## 8 11001007601 Census Tract 76.01, District of Columbia, District of Columbia
## 9 11001009604 Census Tract 96.04, District of Columbia, District of Columbia
## 10 11001009803 Census Tract 98.03, District of Columbia, District of Columbia
## variable estimate moe geometry
## 1 B19013_001 116250 15922 POLYGON ((-77.03195 38.9096...
## 2 B19013_001 80682 37845 POLYGON ((-77.02971 38.9376...
## 3 B19013_001 109863 24472 POLYGON ((-76.98364 38.8898...
## 4 B19013_001 54432 50966 POLYGON ((-77.00057 38.8309...
## 5 B19013_001 47694 8992 POLYGON ((-76.98341 38.9001...
## 6 B19013_001 160536 52157 POLYGON ((-77.01493 38.9206...
## 7 B19013_001 86733 23440 POLYGON ((-77.07957 38.9334...
## 8 B19013_001 40330 5556 POLYGON ((-76.9901 38.87135...
## 9 B19013_001 72872 13143 POLYGON ((-76.9618 38.89612...
## 10 B19013_001 29000 24869 POLYGON ((-77.00774 38.8356...As shown in the example call, the structure of the object returned by tidycensus resembles the object we’ve become familiar with to this point in the book. For example, median household income data are found in the estimate column with associated margins of error in the moe column, along with a variable ID, GEOID, and Census tract name. However, there are some notable differences. The geometry column contains polygon feature geometry for each Census tract, allowing for a linking of the estimates and margins of error with their corresponding locations in Washington, DC. Beyond that, the object is associated with coordinate system information - using the NAD 1983 geographic coordinate system in which Census geographic datasets are stored by default.
6.1.1 Basic mapping of sf objects with plot()
Such geographic information can be difficult to understand without visualization. As the returned object is a simple features object, both geometry and attributes can be visualized with plot(). Key here is specifying the name of the column to be plotted inside of brackets, which in this case is "estimate".
plot(dc_income["estimate"])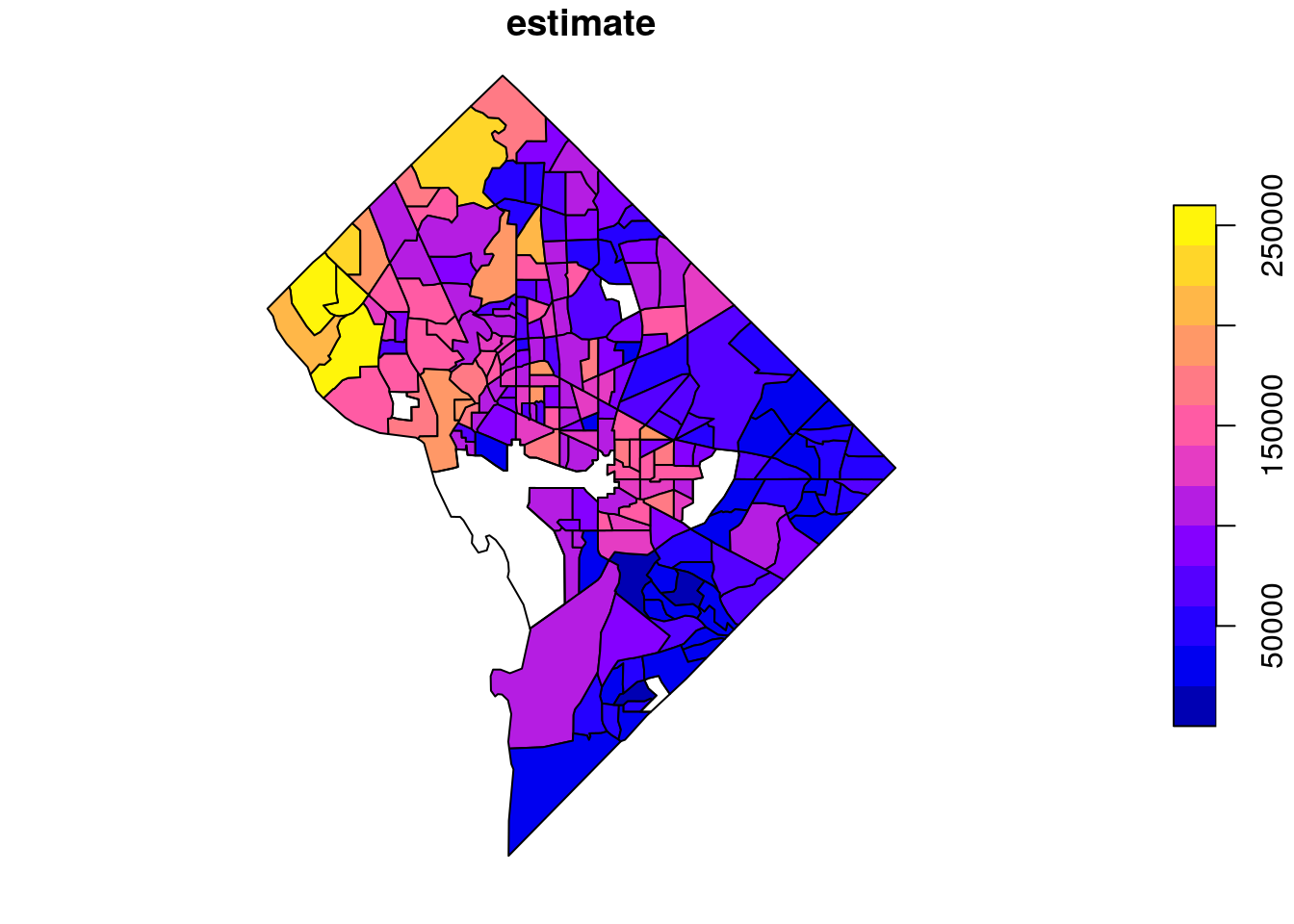
Figure 6.1: Base R plot of median household income by tract in DC
The plot() function returns a simple map showing income variation in Washington, DC. Wealthier areas, as represented with warmer colors, tend to be located in the northwestern part of the District. NA values are represented on the map in white. If desired, the map can be modified further with base plotting functions.
The remainder of this chapter, however, will focus on map-making with additional data visualization packages in R. This includes the popular ggplot2 package for visualization, which supports direct visualization of simple features objects; the tmap package for thematic mapping, and the leaflet package for interactive map-making which calls the Leaflet JavaScript framework directly from R.
6.2 Map-making with ggplot2 and geom_sf
As illustrated in Section 5.2, geom_sf() in ggplot2 can be used for quick plotting of sf objects using familiar ggplot2 syntax. geom_sf() goes far beyond simple cartographic display. The full power of ggplot2 is available to create highly customized maps and geographic data visualizations.
6.2.1 Choropleth mapping
One of the most common ways to visualize statistical information on a map is with choropleth mapping. Choropleth maps use shading to represent how underlying data values vary by feature in a spatial dataset. The income plot of Washington, DC shown earlier in this chapter is an example of a choropleth map.
In the example below, tidycensus is used to obtain linked ACS and spatial data on median age by state for the 50 US states plus the District of Columbia and Puerto Rico. For national maps, it is often preferable to generate insets of Alaska, Hawaii, and Puerto Rico so that they can all be viewed comparatively with the continental United States. We’ll use the shift_geometry() function in tigris to shift and rescale these areas for national mapping. The argument resolution = "20m" is necessary here for appropriate results, as it will omit the long archipelago of islands to the northwest of Hawaii.
library(tidycensus)
library(tidyverse)
library(tigris)
us_median_age <- get_acs(
geography = "state",
variables = "B01002_001",
year = 2019,
survey = "acs1",
geometry = TRUE,
resolution = "20m"
) %>%
shift_geometry()
plot(us_median_age$geometry)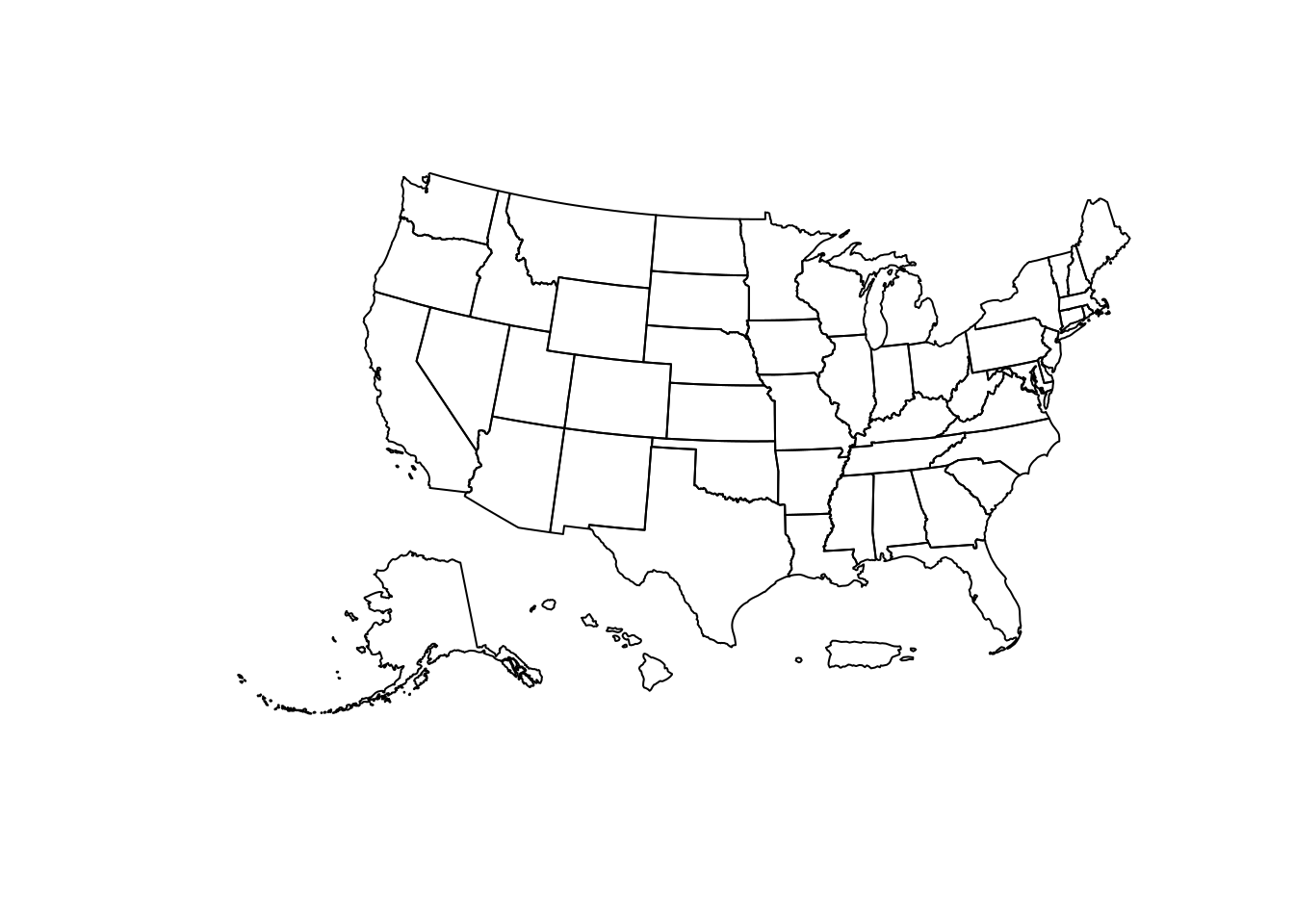
Figure 6.2: Plot of shifted and rescaled US geometry
The state polygons can be styled using ggplot2 conventions and the geom_sf() function. With two lines of ggplot2 code, a basic map of median age by state can be created with ggplot2 defaults.
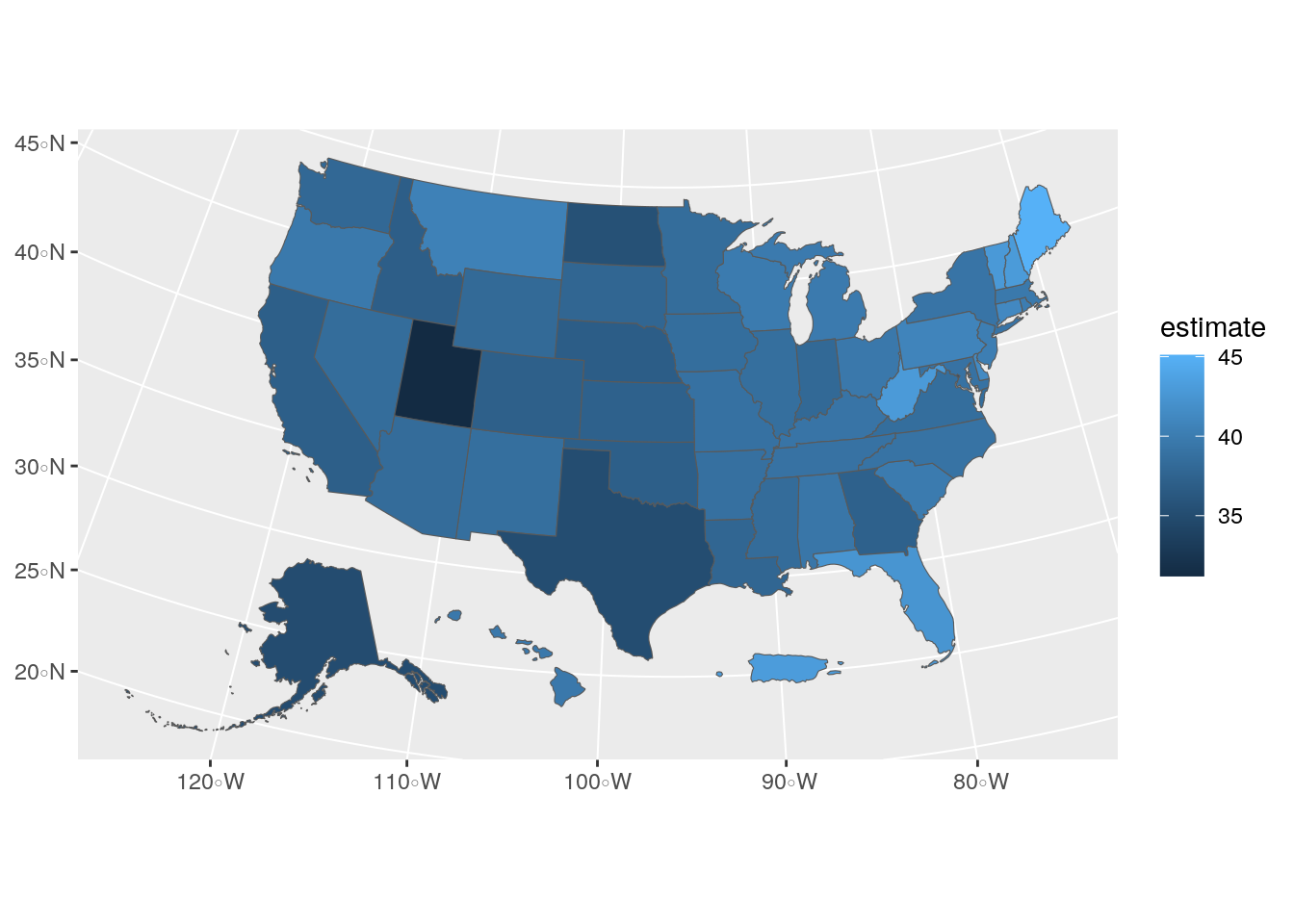
Figure 6.3: US choropleth map with ggplot2 defaults
The geom_sf() function in the above example interprets the geometry of the sf object (in this case, polygon) and visualizes the result as a filled choropleth map. In this case, the ACS estimate of median age is mapped to the default blue dark-to-light color ramp in ggplot2, highlighting the youngest states (such as Utah) with darker blues and the oldest states (such as Maine) with lighter blues.
6.2.2 Customizing ggplot2 maps
In many cases, map-makers using ggplot2 will want to customize this graphic further. For example, a designer may want to modify the color palette and reverse it so that darker colors represent older areas. The map would also benefit from some additional information describing its content and data sources. These modifications can be specified in the same way a user would update a regular ggplot2 graphic. The scale_fill_distiller() function allows users to specify a ColorBrewer palette to use for the map, which includes a wide range of sequential, diverging, and qualitative color palettes (Brewer, Hatchard, and Harrower 2003). The labs() function can then be used to add a title, caption, and better legend label to the plot. Finally, ggplot2 cartographers will often want to use the theme_void() function to remove the background and gridlines from the map.
ggplot(data = us_median_age, aes(fill = estimate)) +
geom_sf() +
scale_fill_distiller(palette = "RdPu",
direction = 1) +
labs(title = " Median Age by State, 2019",
caption = "Data source: 2019 1-year ACS, US Census Bureau",
fill = "ACS estimate") +
theme_void()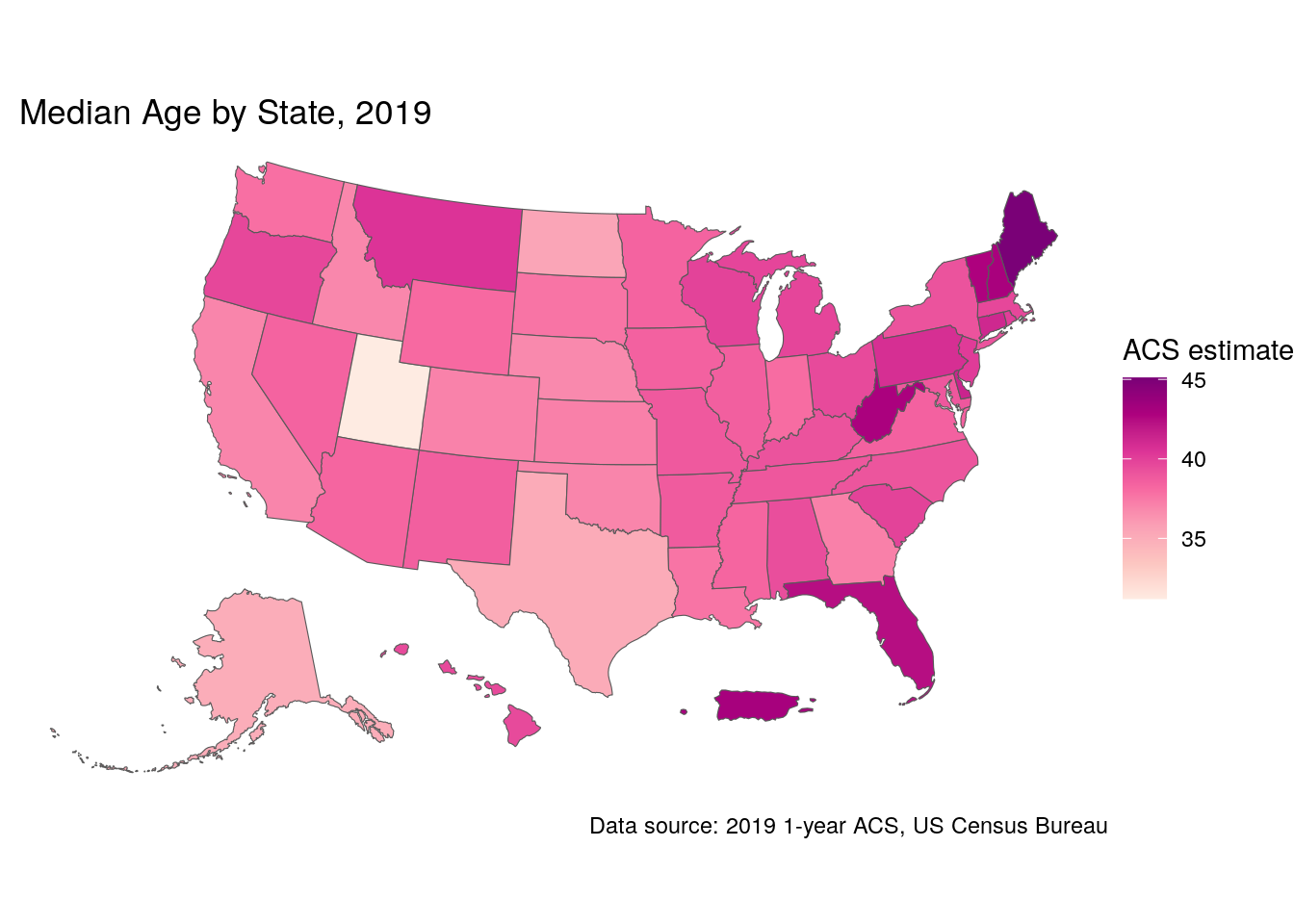
Figure 6.4: Styled choropleth of US median age with ggplot2
6.3 Map-making with tmap
For ggplot2 users, geom_sf() offers a familiar interface for mapping data obtained from the US Census Bureau. However, ggplot2 is far from the only option for cartographic visualization in R. The tmap package (Tennekes 2018) is an excellent alternative for mapping in R that includes a wide range of functionality for custom cartography. The section that follows is an overview of several cartographic techniques implemented with tmap for visualizing US Census data. A full treatment of best practices in cartographic design is beyond the scope of this section; recommended resources for learning more include Peterson (2020) and Brewer (2016).
To begin, we will obtain race and ethnicity data from the 2020 decennial US Census using the get_decennial() function. We’ll be looking at data on non-Hispanic white, non-Hispanic Black, Asian, and Hispanic populations for Census tracts in Hennepin County, Minnesota.
hennepin_race <- get_decennial(
geography = "tract",
state = "MN",
county = "Hennepin",
variables = c(
Hispanic = "P2_002N",
White = "P2_005N",
Black = "P2_006N",
Native = "P2_007N",
Asian = "P2_008N"
),
summary_var = "P2_001N",
year = 2020,
geometry = TRUE
) %>%
mutate(percent = 100 * (value / summary_value))| GEOID | NAME | variable | value | summary_value | geometry | percent |
|---|---|---|---|---|---|---|
| 27053026707 | Census Tract 267.07, Hennepin County, Minnesota | Hispanic | 175 | 5188 | MULTIPOLYGON (((-93.49271 4… | 3.3731689 |
| 27053026707 | Census Tract 267.07, Hennepin County, Minnesota | White | 4215 | 5188 | MULTIPOLYGON (((-93.49271 4… | 81.2451812 |
| 27053026707 | Census Tract 267.07, Hennepin County, Minnesota | Black | 258 | 5188 | MULTIPOLYGON (((-93.49271 4… | 4.9730146 |
| 27053026707 | Census Tract 267.07, Hennepin County, Minnesota | Native | 34 | 5188 | MULTIPOLYGON (((-93.49271 4… | 0.6553585 |
| 27053026707 | Census Tract 267.07, Hennepin County, Minnesota | Asian | 178 | 5188 | MULTIPOLYGON (((-93.49271 4… | 3.4309946 |
| 27053021602 | Census Tract 216.02, Hennepin County, Minnesota | Hispanic | 224 | 5984 | MULTIPOLYGON (((-93.38036 4… | 3.7433155 |
| 27053021602 | Census Tract 216.02, Hennepin County, Minnesota | White | 4581 | 5984 | MULTIPOLYGON (((-93.38036 4… | 76.5541444 |
| 27053021602 | Census Tract 216.02, Hennepin County, Minnesota | Black | 658 | 5984 | MULTIPOLYGON (((-93.38036 4… | 10.9959893 |
| 27053021602 | Census Tract 216.02, Hennepin County, Minnesota | Native | 21 | 5984 | MULTIPOLYGON (((-93.38036 4… | 0.3509358 |
| 27053021602 | Census Tract 216.02, Hennepin County, Minnesota | Asian | 188 | 5984 | MULTIPOLYGON (((-93.38036 4… | 3.1417112 |
We’ve returned ACS data in tidycensus’s regular “tidy” or long format, which will be useful in a moment for comparative map-making, and completed some basic data wrangling tasks learned in Chapter 3 to calculate group percentages. To get started mapping this data, we’ll extract a single group from the dataset to illustrate how tmap works.
6.3.1 Choropleth maps with tmap
tmap’s map-making syntax will be somewhat familiar to users of ggplot2, as it uses the concept of layers to specify modifications to the map. The map object is initialized with tm_shape(), which then allows us to view the Census tracts with tm_polygons(). We’ll first filter our long-form spatial dataset to get a unique set of tract polygons, then visualize them.
library(tmap)
hennepin_black <- filter(hennepin_race,
variable == "Black")
tm_shape(hennepin_black) +
tm_polygons()
Figure 6.5: Basic polygon plot with tmap
We get a default view of Census tracts in Hennepin County, Minnesota. Alternatively, the tm_fill() function can be used to produce choropleth maps, as illustrated in the ggplot2 examples above.
tm_shape(hennepin_black) +
tm_polygons(col = "percent")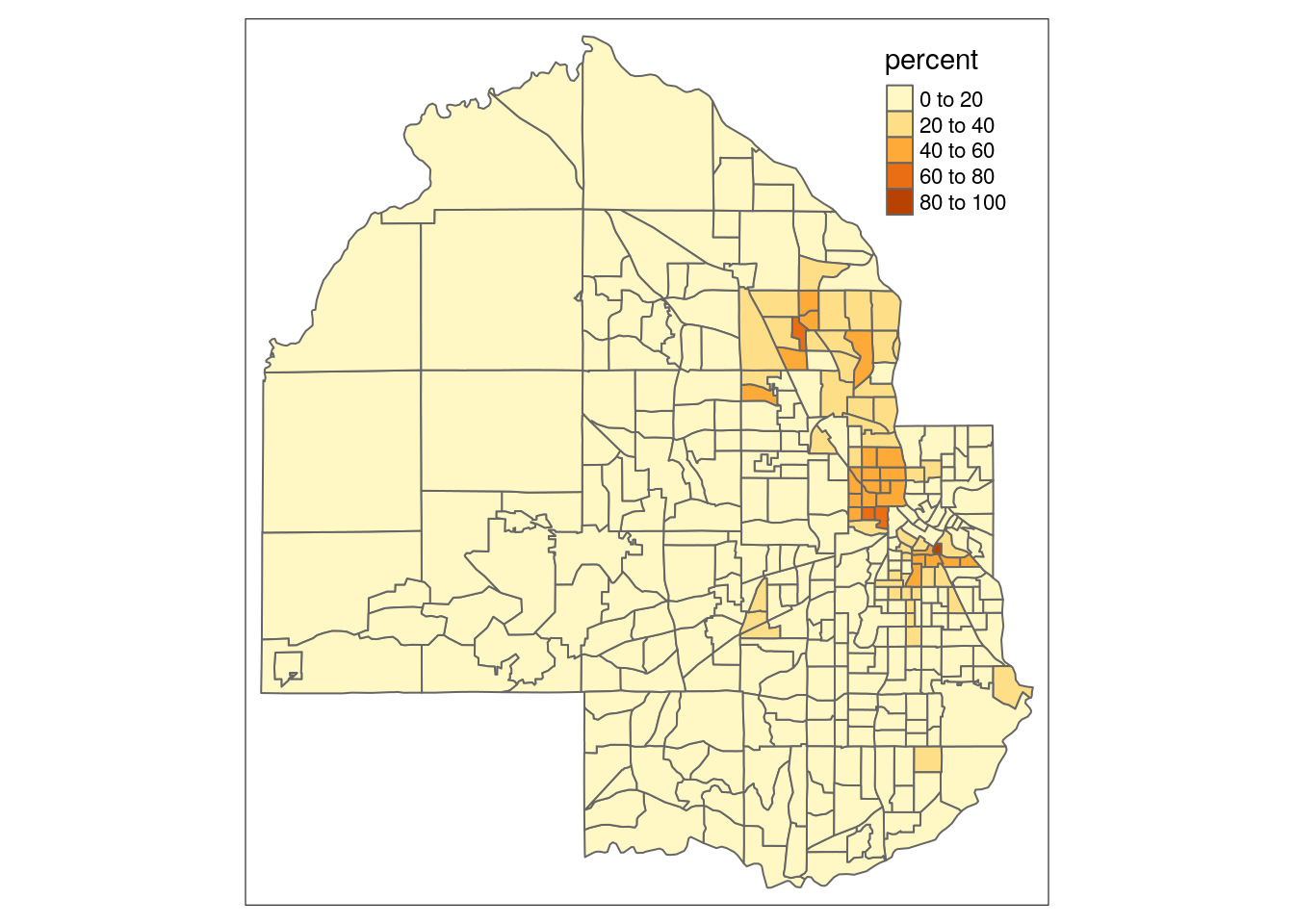
Figure 6.6: Basic choropleth with tmap
You’ll notice that tmap uses a classed color scheme rather than the continuous palette used by ggplot2, by default. This involves the identification of “classes” in the distribution of data values and mapping a color from a color palette to data values that belong to each class. The default classification scheme used by tm_fill() is "pretty", which identifies clean-looking intervals in the data based on the data range. In this example, data classes change every 20 percent. However, this approach will always be sensitive to the distribution of data values. Let’s take a look at our data distribution to understand why:
hist(hennepin_black$percent)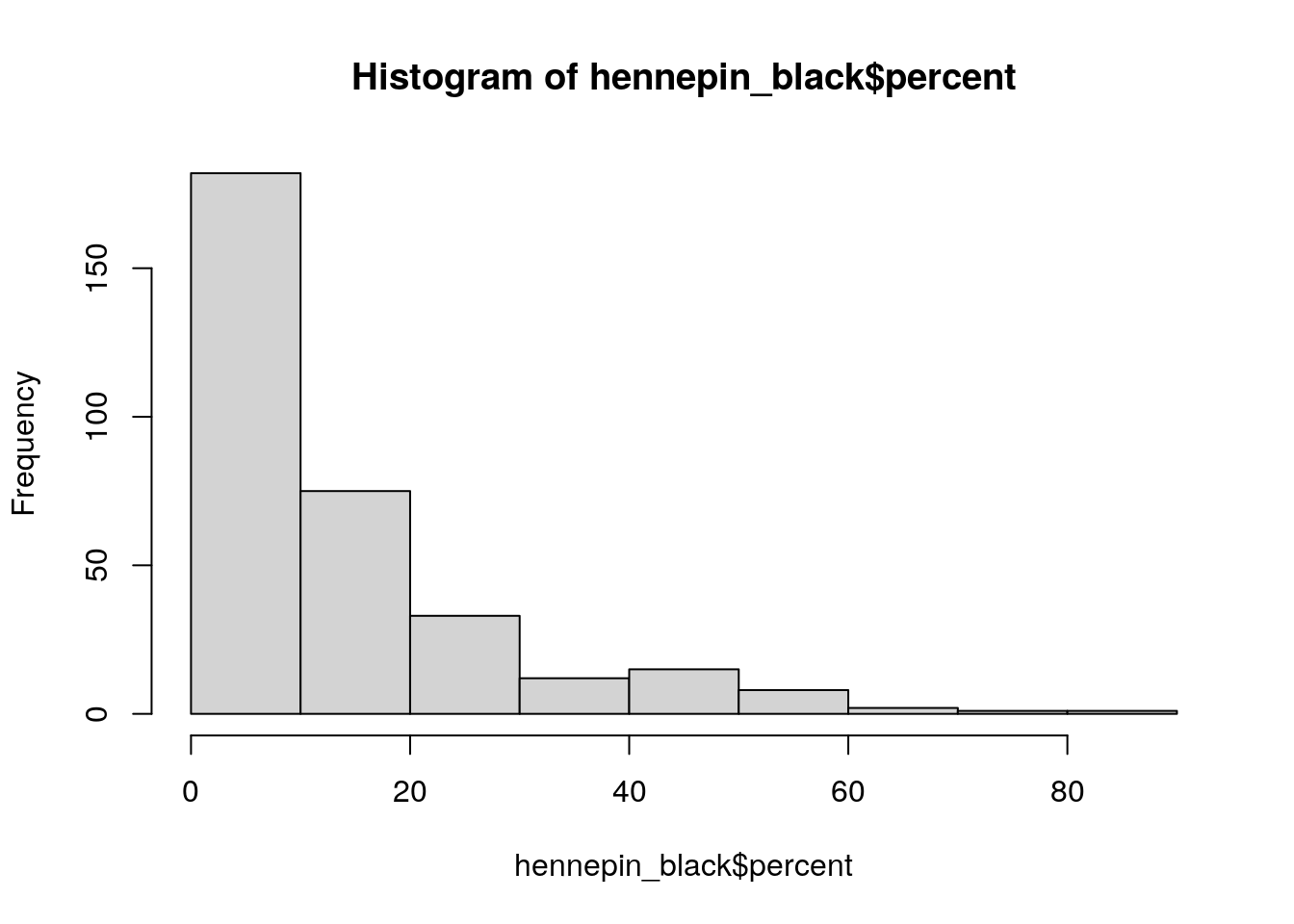
Figure 6.7: Base R histogram of percent Black by Census tract
As the histogram illustrates, most Census tracts in Hennepin County have Black populations below 20 percent. In turn, variation within this bucket is not visible on the map given that most tracts fall into one class. The style argument in tm_fill() supports a number of other methods for classification, including quantile breaks ("quantile"), equal intervals ("equal"), and Jenks natural breaks ("jenks"). Let’s switch to quantiles below, where each class will contain the same number of Census tracts. We can also change the color palette and add some contextual text as we did with ggplot2.
tm_shape(hennepin_black) +
tm_polygons(col = "percent",
style = "quantile",
n = 5,
palette = "Purples",
title = "2020 US Census") +
tm_layout(title = "Percent Black\nby Census tract",
frame = FALSE,
legend.outside = TRUE)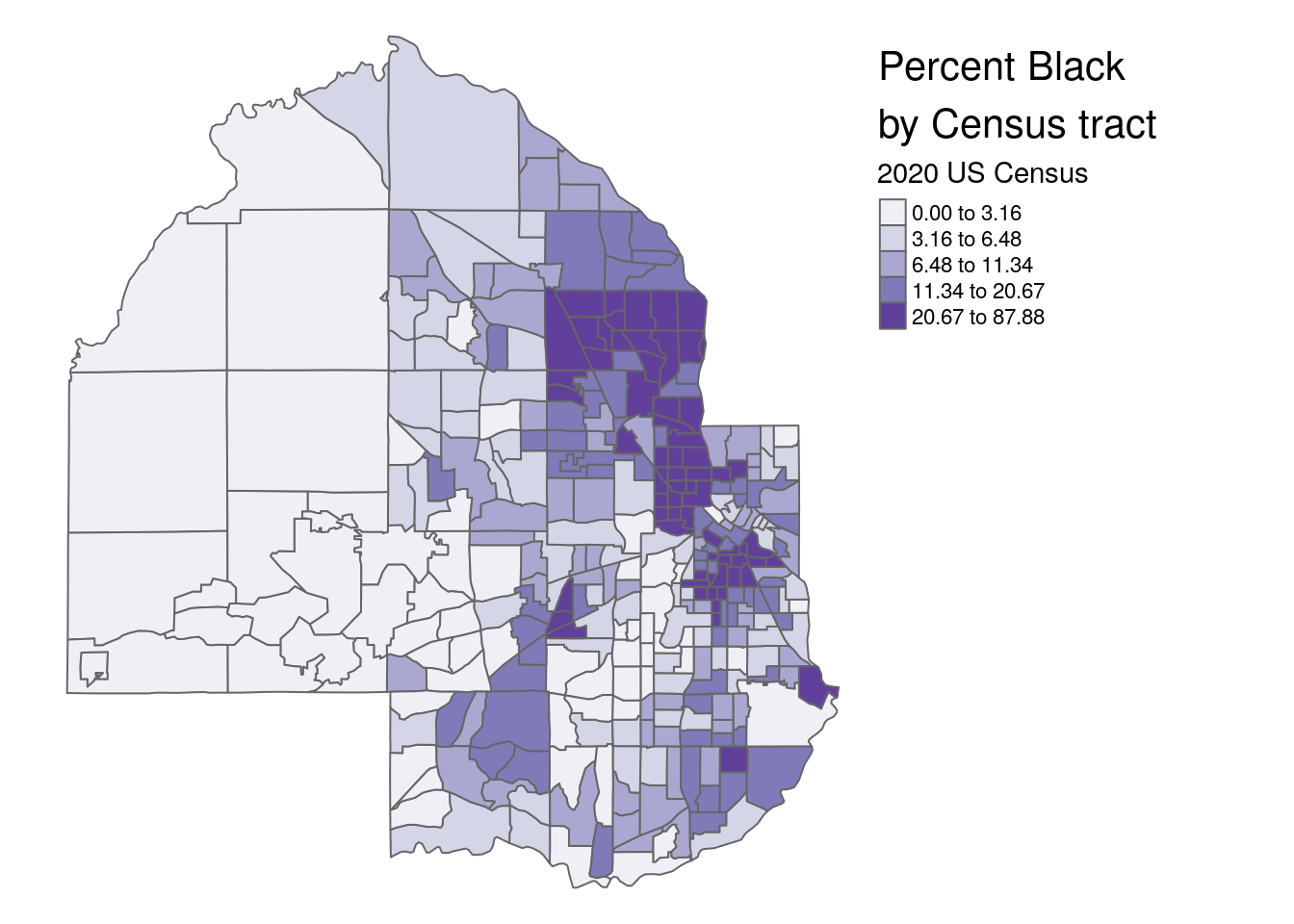
Figure 6.8: tmap choropleth with options
Switching from the default classification scheme to quantiles reveals additional neighborhood-level heterogeneity in Hennepin County’s Black population in suburban areas. However, it does mask some heterogeneity in Minneapolis as the top class now includes values ranging from 21 percent to 88 percent. A “compromise” solution commonly used in GIS cartography applications is the Jenks natural-breaks method, which uses an algorithm to identify meaningful breaks in the data for bin boundaries (Jenks 1967). To assist with understanding how the different classification methods work, the legend.hist argument in tm_polygons() can be set to TRUE, adding a histogram to the map with bars colored by the values used on the map.
tm_shape(hennepin_black) +
tm_polygons(col = "percent",
style = "jenks",
n = 5,
palette = "Purples",
title = "2020 US Census",
legend.hist = TRUE) +
tm_layout(title = "Percent Black\nby Census tract",
frame = FALSE,
legend.outside = TRUE,
bg.color = "grey70",
legend.hist.width = 5,
fontfamily = "Verdana")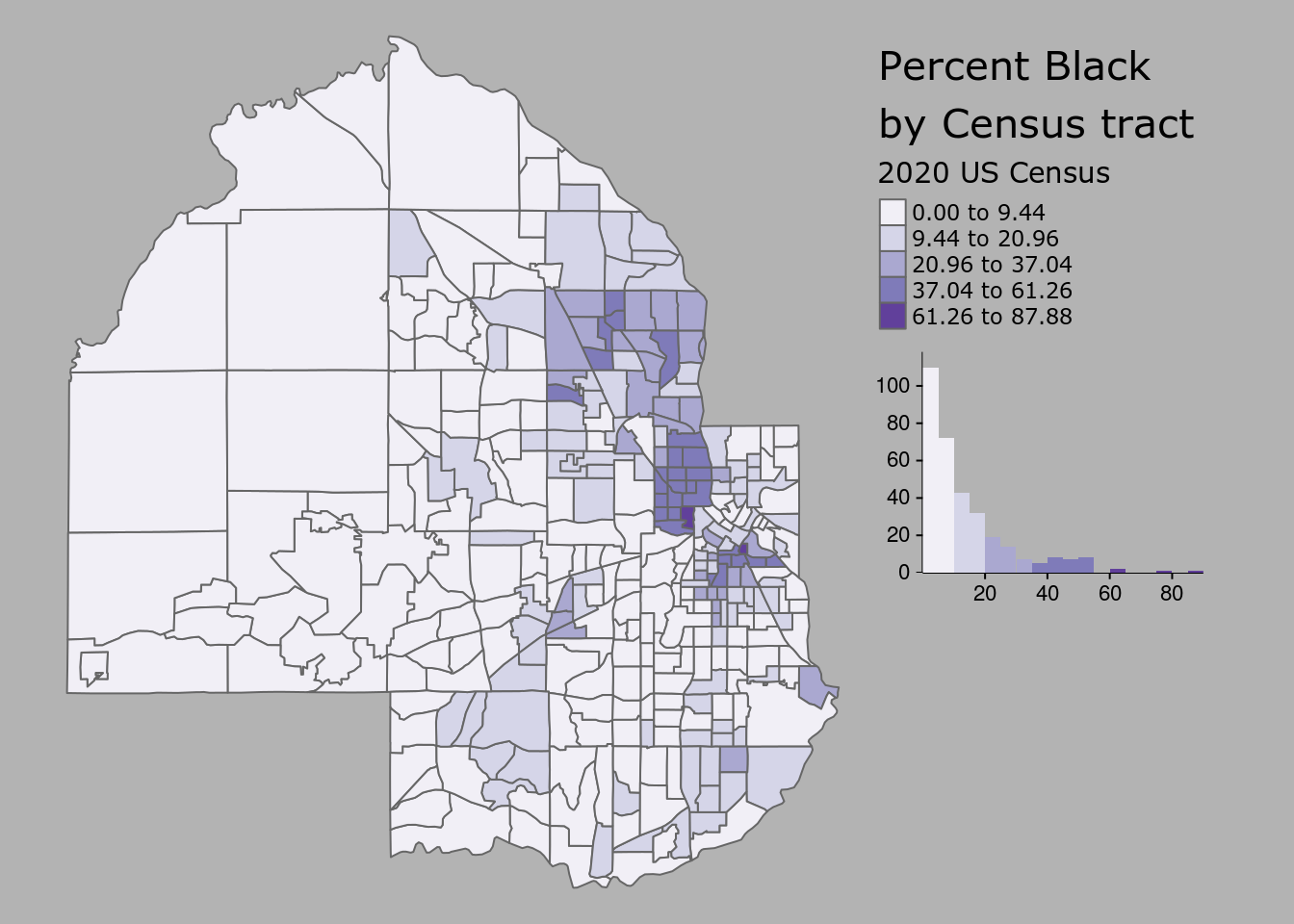
Figure 6.9: Styled tmap choropleth
The tm_layout() function is used to customize the styling of the map and histogram, and has many more options beyond those shown that can be viewed in the function’s documentation.
6.3.2 Adding reference elements to a map
The choropleth map as illustrated in the previous example represents the data as a statistical graphic, with both a map and histogram showing the underlying data distribution. Cartographers coming to R from a desktop GIS background will be accustomed to adding a variety of reference elements to their map layouts to provide additional geographical context to the map. These elements may include a basemap, north arrow, and scale bar, all of which can be accommodated by tmap.
The quickest way to get basemaps for use with tmap is the rosm package Dunnington (2019), which helps users access freely-available basemaps from a variety of different providers. In some cases, users will want to design their own basemaps for use in their R projects. The example shown here uses the mapboxapi R package K. Walker (2021c), which gives users with a Mapbox account access to pre-designed Mapbox basemaps as well as custom-designed basemaps in Mapbox Studio.
To use Mapbox basemaps with mapboxapi and tmap, you’ll first need a Mapbox account and access token. Mapbox accounts are free; register at the Mapbox website then find your access token. In R, this token can be set with the mb_access_token() function in mapboxapi.
library(mapboxapi)
# Replace with your token below
mb_access_token("pk.ey92lksd...")Once set, basemap tiles for an input spatial dataset can be fetched with the get_static_tiles() function in mapboxapi, which interacts with the Mapbox Static Tiles API. Mapbox Studio users can design a custom basemap style and use the custom style ID along with their username to fetch tiles from that style for mapping; any Mapbox user can also use the default Mapbox styles by supplying username = "mapbox" and the appropriate style ID. The level of detail of the underlying basemap can be adjusted with the zoom argument.
# If you don't have a Mapbox style to use, replace style_id with "light-v9"
# and username with "mapbox". If you do, replace those arguments with your
# style ID and user name.
hennepin_tiles <- get_static_tiles(
location = hennepin_black,
zoom = 10,
style_id = "ckedp72zt059t19nssixpgapb",
username = "kwalkertcu"
)In most cases, users should choose a muted, monochrome basemap when designing a map with a choropleth overlay to avoid confusing blending of colors.
These basemap tiles are layered into the familiar tmap workflow with the tm_rgb() function. To show the underlying basemap, users should modify the transparency of the Census tract polygons with the alpha argument. Additional tmap functions then add ancillary map elements. tm_scale_bar() adds a scale bar; tm_compass() adds a north arrow; and tm_credits() helps cartographers give credit for the basemap, which is required when using Mapbox and OpenStreetMap tiles.
tm_shape(hennepin_tiles) +
tm_rgb() +
tm_shape(hennepin_black) +
tm_polygons(col = "percent",
style = "jenks",
n = 5,
palette = "Purples",
title = "2020 US Census",
alpha = 0.7) +
tm_layout(title = "Percent Black\nby Census tract",
legend.outside = TRUE,
fontfamily = "Verdana") +
tm_scale_bar(position = c("left", "bottom")) +
tm_compass(position = c("right", "top")) +
tm_credits("(c) Mapbox, OSM ",
bg.color = "white",
position = c("RIGHT", "BOTTOM"))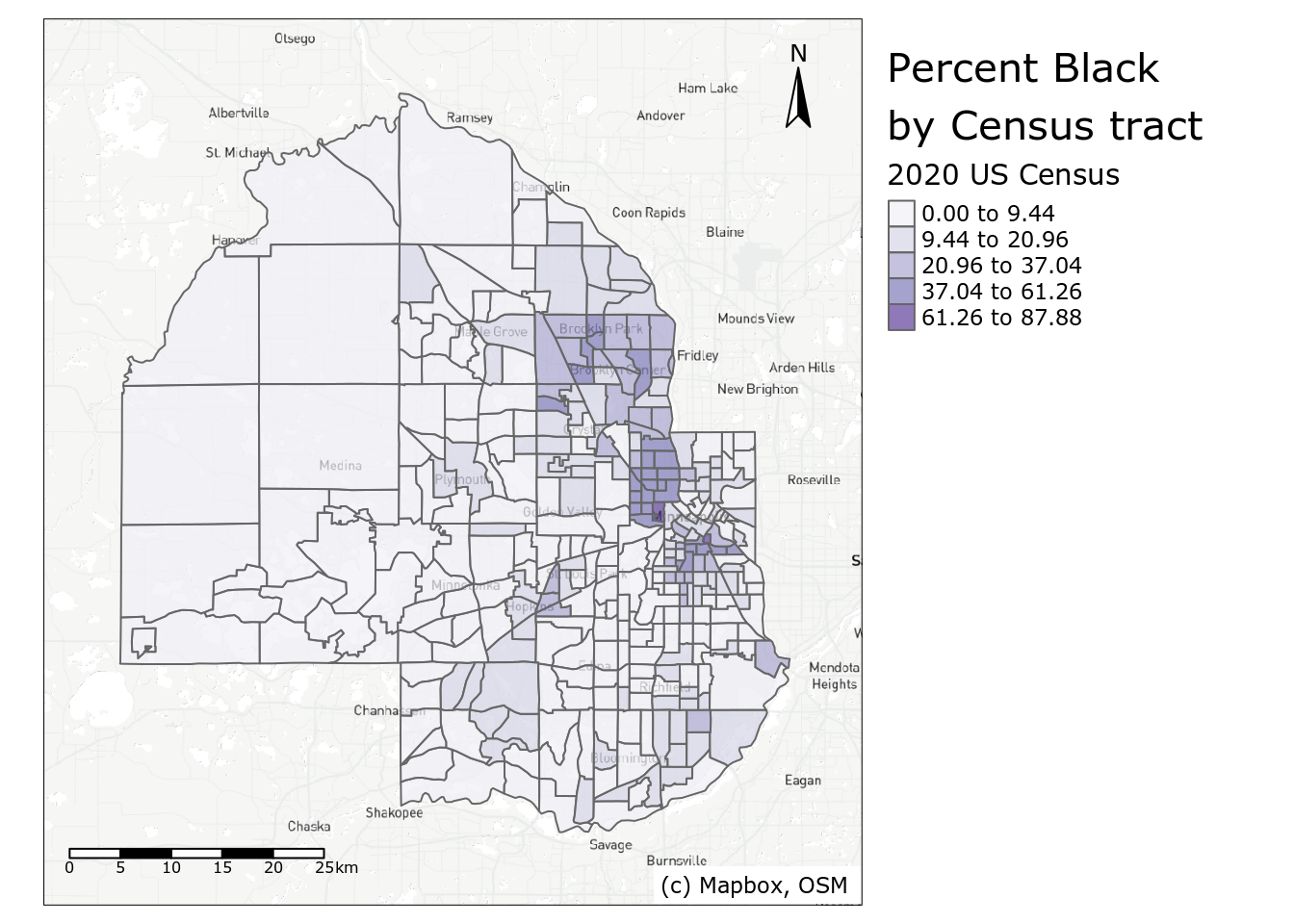
Figure 6.10: Map of percent Black in Hennepin County with reference elements
Depending on the shape of your Census data, the position arguments in tm_scale_bar(), tm_compass(), and tm_credits() can be modified to organize ancillary map elements appropriately. When capitalized (as used in tm_credits()), the element will be positioned tighter to the map frame.
6.3.3 Choosing a color palette
The examples shown in this chapter thus far have used a variety of color palettes to display statistical variation on choropleth maps. Software packages like sf, ggplot2, and tmap will have color palettes built in as “defaults”; I’ve shown the default palettes for all three, then changed the palettes used in ggplot2 and in tmap. So how do you go about choosing an appropriate color palette? There are a variety of considerations to take into account.
First, it is important to understand the type of data you are working with. If your data are quantitative - that is, expressed with numbers, which you’ll commonly be working with using Census data - you’ll want a color palette that can show the statistical variation in your data correctly. In the demographic examples shown above, decennial Census data range from a low value to a high value. This type of information is effectively represented with a sequential color palette. Sequential color palettes use either a single hue or related hues then modify the color lightness or intensity to generate a sequence of colors. An example single-hue palette is the “Purples” ColorBrewer palette used in the map above.

Figure 6.11: Sequential ‘Purples’ color palette
With this palette, lighter colors should generally be used to represent lower data values, and darker values should represent higher values, suggesting a greater density/concentration of that attribute. In other color palettes, however, the more intense colors may be the lighter colors and should be used accordingly to represent data values. This is the case with the popular viridis color palettes, implemented in R with the viridis package (Garnier et al. 2021) and shown below.

Figure 6.12: Sequential ‘viridis’ color palette
Diverging color palettes are best used when the cartographer wants to highlight extreme values on either end of the data distribution and represent neutral values in the middle. The example shown below is the ColorBrewer “RdBu” palette.

Figure 6.13: Diverging ‘RdBu’ color palette
For Census data mapping, diverging palettes are well-suited to maps that visualize change over time. A map of population change using a diverging palette would highlight extreme population loss and extreme population gain with intense colors on either end of the palette, and represent minimal population change with a muted, neutral color in the middle.
Qualitative palettes are appropriate for categorical data, as they represent data values with unique, unordered hues. A good example is the “Set1” color palette shown below.

Figure 6.14: Categorical ‘Set1’ color palette
While maps of Census data as returned by tidycensus will generally use sequential or diverging color palettes (given the quantitative nature of Census data), derived data products may require qualitative palettes. Illustrative examples in this book include categorical dot-density maps (addressed later in this chapter) and visualizations of geodemographic clusters, explored in Section 8.5.1.
Choosing an appropriate color palette for your maps can be a challenge. Fortunately, the ColorBrewer and viridis palettes are appropriate for a wide range of cartographic use cases and have built-in support in ggplot2 and tmap. An excellent tool for helping decide on a color palette is tmap’s Palette Explorer app, accessible with the command tmaptools::palette_explorer(). Run this command in your R console to launch an interactive app that helps you explore different color scenarios using ColorBrewer and viridis palettes. Notably, the app includes a color blindness simulator to help you choose color palettes that are color blindness friendly.
6.3.4 Alternative map types with tmap
Choropleth maps are a core part of the Census data analyst’s toolkit, but they are not ideal for every application. In particular, choropleth maps are best suited for visualizing rates, percentages, or statistical values that are normalized for the population of areal units. They are not ideal when the analyst wants to compare counts (or estimated counts) themselves, however. Choropleth maps of count data may ultimately reflect the underlying size of a baseline population; additionally, given that the counts are compared visually relative to the irregular shape of the polygons, choropleth maps can make comparisons difficult.
6.3.4.1 Graduated symbols
An alternative commonly used to visualize count data is the graduated symbol map. Graduated symbol maps use shapes referenced to geographic units that are sized relative to a data attribute. The example below uses tmap’s tm_bubbles() function to create a graduated symbol map of the Black population in Hennepin County, mapping the estimate column.
tm_shape(hennepin_black) +
tm_polygons() +
tm_bubbles(size = "value", alpha = 0.5,
col = "navy",
title.size = "Non-Hispanic Black - 2020 US Census") +
tm_layout(legend.outside = TRUE,
legend.outside.position = "bottom")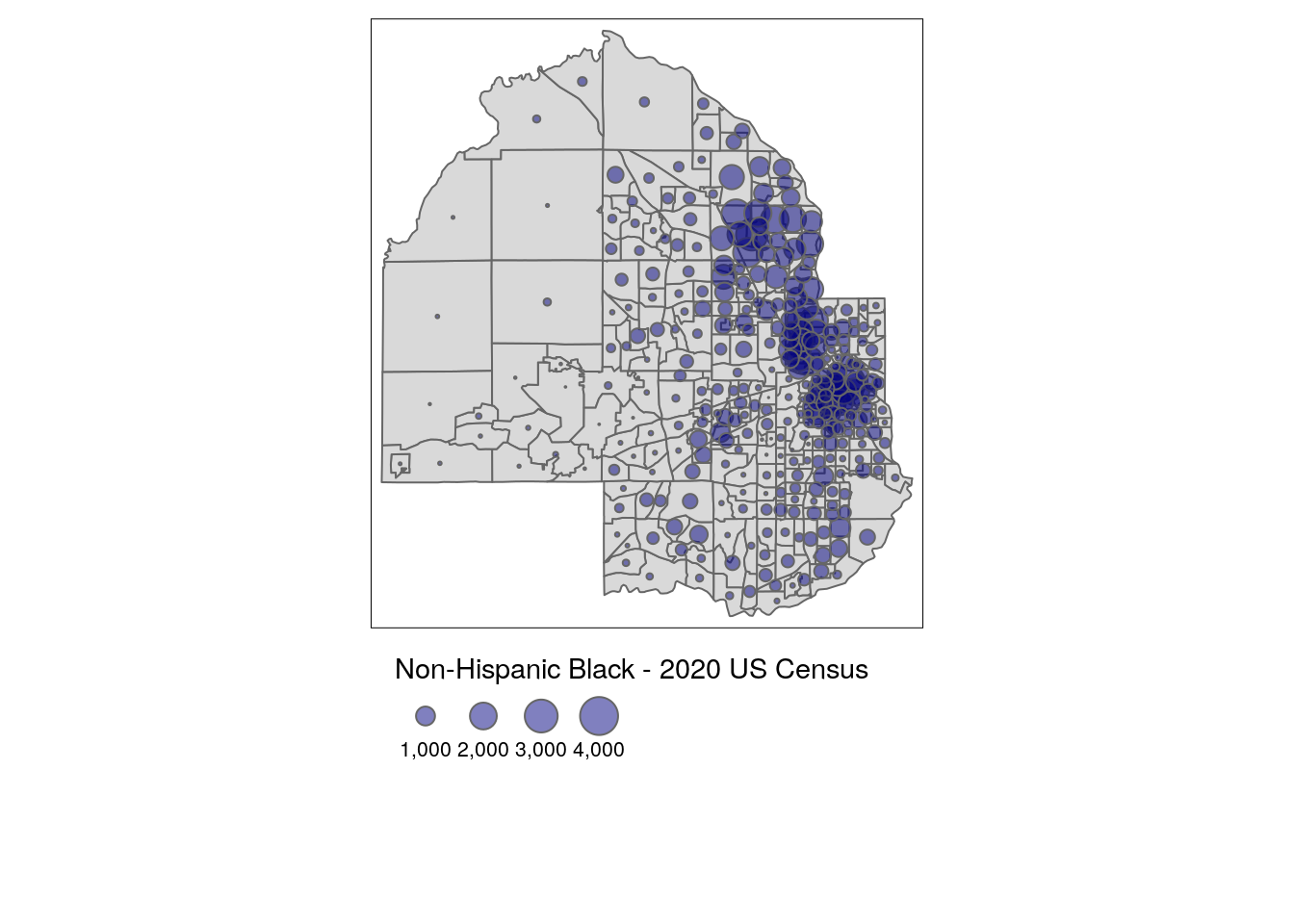
Figure 6.15: Graduated symbols with tmap
The visual comparisons on the map are made between the circles, not the polygons themselves, reflecting differences between population sizes.
6.3.4.2 Faceted maps
Given that the long-form race & ethnicity dataset returned by tidycensus includes information on five groups, a cartographer may want to visualize those groups comparatively. A single choropleth map cannot effectively visualize five demographic attributes simultaneously, and creating five separate maps can be tedious. A solution to this is using faceting, a concept introduced in Chapter ??.
Faceted maps in tmap are created with the tm_facets() function. The by argument specifies the column to be used to identify unique groups in the data. The remaining code is familiar tmap code; in this example, tm_fill() is preferred to tm_polygons() to hide the Census tract borders given the smaller sizes of the maps. The legend is also moved with the legend.position argument in tm_layout() to fill the empty space in the faceted map.
tm_shape(hennepin_race) +
tm_facets(by = "variable", scale.factor = 4) +
tm_fill(col = "percent",
style = "quantile",
n = 6,
palette = "Blues",
title = "Percent (2020 US Census)",) +
tm_layout(bg.color = "grey",
legend.position = c(-0.7, 0.15),
panel.label.bg.color = "white")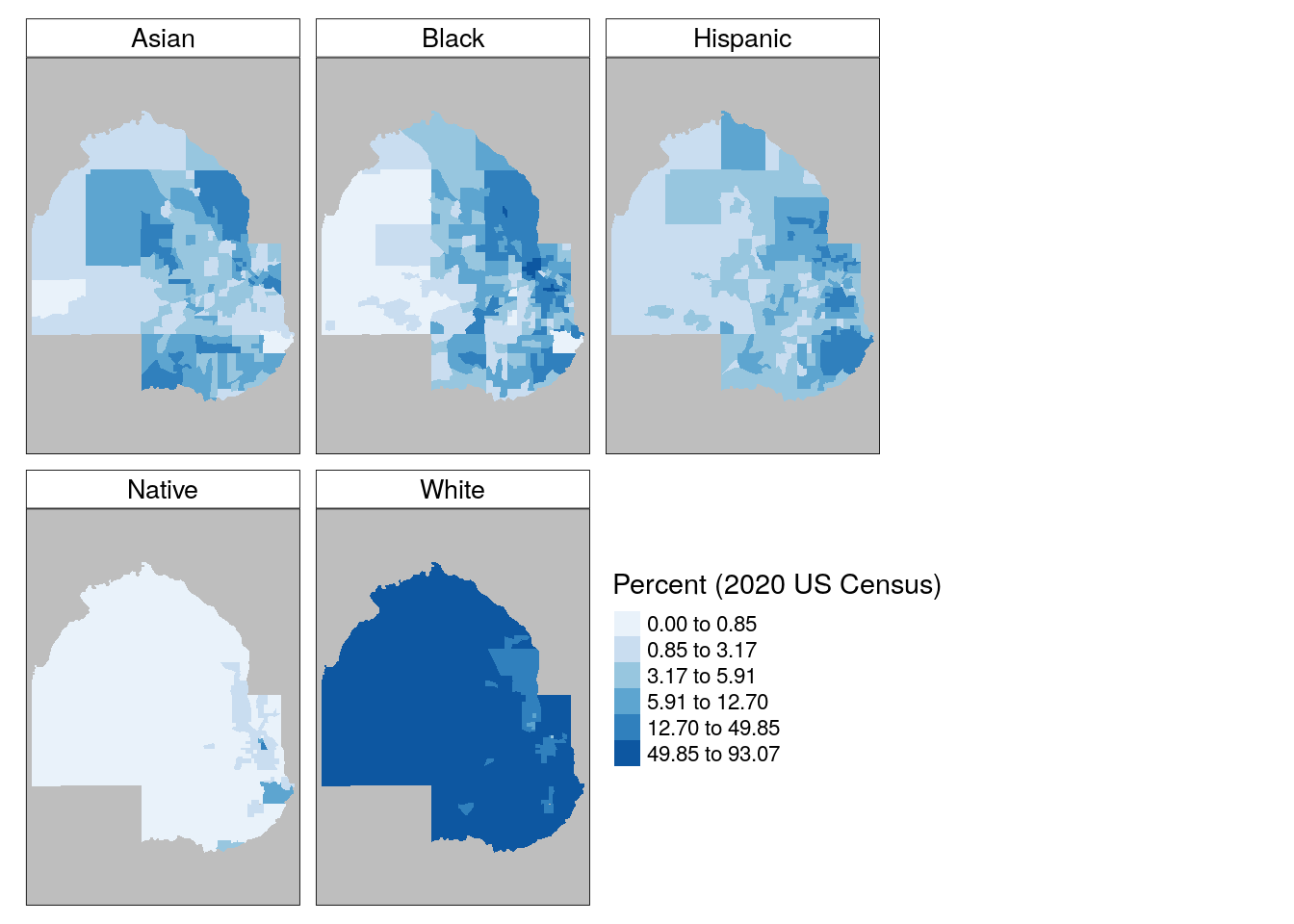
Figure 6.16: Faceted map with tmap
The faceted maps do a good job of showing variations in each group in comparative context. However, the common legend and classification scheme used means that within-group variation is suppressed relative to the need to show consistent comparisons between groups. In turn, the “White” subplot shows little variation among Census tracts in Hennepin County given the large size of that group in the area. One additional disadvantage of separate maps by group is that they do not show neighborhood heterogeneity and diversity as well as they could. A popular alternative for visualizing within-unit heterogeneity is the dot-density map, covered below.
6.3.4.3 Dot-density maps
Dot-density maps scatter dots within areal units relative to the size of a data attribute. This cartographic method is intended to show attribute density through the dot distributions; for a Census map, in areas where the dots are dense, more people live there, whereas sparsely positioned dots reflect sparsity of population. Dot-density maps can also incorporate categories in the data to visualize densities of different subgroups simultaneously.
The as_dot_density() function in tidycensus helps users get Census data ready for dot-density visualization. For an input dataset, the function requires specifying a value column that represents the data attribute to be visualized, and a values_per_dot value that determines how many data values each dot should represent. The group column then partitions dots by group and shuffles their visual ordering on the map so that no one group occludes other groups.
In this example, we specify value = "estimate" to visualize the data from the 2020 US Census; values_per_dot = 100 for a data to dots ratio of 100 people per dot; and group = "variables" to partition dots by racial / ethnic group on the map.
hennepin_dots <- hennepin_race %>%
as_dot_density(
value = "value",
values_per_dot = 100,
group = "variable"
)The map itself is created with the tm_dots() function, which in this example is combined with a background map using tm_polygons() to show the relative racial and ethnic heterogeneity of Census tracts in Hennepin County.
background_tracts <- filter(hennepin_race, variable == "White")
tm_shape(background_tracts) +
tm_polygons(col = "white",
border.col = "grey") +
tm_shape(hennepin_dots) +
tm_dots(col = "variable",
palette = "Set1",
size = 0.005,
title = "1 dot = 100 people") +
tm_layout(legend.outside = TRUE,
title = "Race/ethnicity,\n2020 US Census")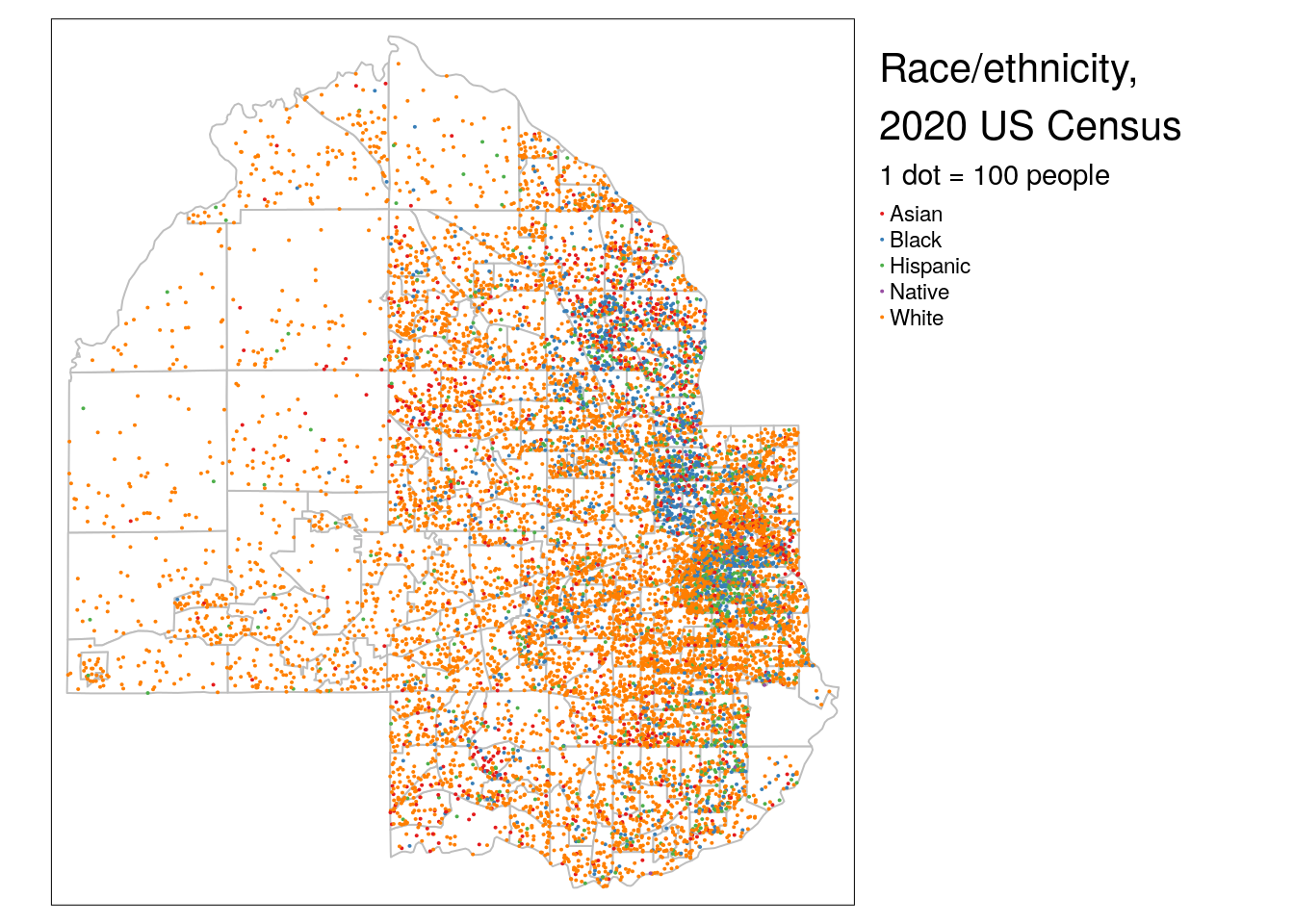
Figure 6.17: Dot-density map with tmap
Issues with dot-density maps can include overplotting of dots which can make legibility a problem; experiment with different dot sizes and dots to data ratios to improve this. Additionally, the use of Census tract polygons to generate the dots can cause visual issues. As dots are placed randomly within Census tract polygons, they in many cases will be placed in locations where no people live (such as lakes in Hennepin County). Dot distributions will also follow tract boundaries, which can create an artificial impression of abrupt changes in population distributions along polygon boundaries (as seen on the example map). A solution is the dasymetric dot-density map (K. E. Walker 2018), which first removes areas from polygons which are known to be uninhabited then runs the dot-generation algorithm over those modified areas. as_dot_density() includes an argument, erase_water, that will automatically remove water areas from the input shapes before generating dots, avoiding dot placement in large bodies of water. This technique uses the erase_water() function in the tigris package, which is covered in more detail in Section 7.5.
6.4 Cartographic workflows with non-Census data
In many instances, an analyst may possess data that is available at a Census geography but is not available through the ACS or decennial Census. This means that the geometry = TRUE functionality in tidycensus, which automatically enriches data with geographic information, is not possible. In these cases, Census shapes obtained with tigris can be joined to tabular data and then visualized.
This section covers two such workflows. The first reproduces the popular red/blue election map common in presidential election cycles. The second focuses on mapping zip code tabulation areas, or ZCTAs, a geography that represents the spatial location of zip codes (postal codes) in the United States.
6.4.1 National election mapping with tigris shapes
While enumeration units like Census tracts and block groups will generally be used to map Census data, Census shapes representing legal entities are useful for a variety of cartographic purposes. A popular example is the political map, which shows the winner or poll results from an election in a region. We’ll use data from the Cook Political Report to generate a basic red state/blue state map of the 2020 US Presidential election results. This dataset was downloaded on June 5, 2021 and is available at "data/us_vote_2020.csv" in the book GitHub repository.
library(tidyverse)
library(tigris)
# Data source: https://cookpolitical.com/2020-national-popular-vote-tracker
vote2020 <- read_csv("data/us_vote_2020.csv")
names(vote2020)## [1] "state" "called" "final" "dem_votes"
## [5] "rep_votes" "other_votes" "dem_percent" "rep_percent"
## [9] "other_percent" "dem_this_margin" "margin_shift" "vote_change"
## [13] "stateid" "EV" "X" "Y"
## [17] "State_num" "Center_X" "Center_Y" "...20"
## [21] "2016 Margin" "Total 2016 Votes"The data include a wide variety of columns that can be visualized on a map. As discussed in the previous chapter, a comparative map of the United States can use the shift_geometry() function in the tigris package to shift and rescale Alaska and Hawaii. State geometries are available in tigris with the states() function, which should be used with the arguments cb = TRUE and resolution = "20m" to appropriately generalize the state geometries for national mapping.
To create the map, the geometry data obtained with tigris must be joined to the election data from the Cook Political Report. This is accomplished with the left_join() function from dplyr. dplyr’s *_join() family of functions are supported by simple features objects, and work in this context analogous to the common “Join” operations in desktop GIS software. The join functions work by matching values in one or more “key fields” between two tables and merging data from those two tables into a single output table. The most common join functions you’ll use for spatial data are left_join(), which retains all rows from the first dataset and fills non-matching rows with NA values, and inner_join(), which drops non-matching rows in the output dataset.
Let’s try this out by obtaining low-resolution state geometry with tigris, shifting and rescaling with shift_geometry(), then merging the political data to those shapes, matching the NAME column in us_states to the state column in vote2020.
us_states <- states(cb = TRUE, resolution = "20m") %>%
filter(NAME != "Puerto Rico") %>%
shift_geometry()
us_states_joined <- us_states %>%
left_join(vote2020, by = c("NAME" = "state"))Before proceeding we’ll want to do some quality checks. In left_join(), values must match exactly between NAME and state to merge correctly - and this is not always guaranteed when using data from different sources. Let’s check to see if we have any problems:
##
## FALSE
## 51We’ve matched all the 50 states plus the District of Columbia correctly. In turn, the joined dataset has retained the shifted and rescaled geometry of the US states and now includes the election information from the tabular dataset which can be used for mapping. To achieve this structure, specifying the directionality of the join was critical. For spatial information to be retained in a join, the spatial object must be on the left-hand side of the join. In our pipeline, we specified the us_states object first and used left_join() to join the election information to the states object. If we had done this in reverse, we would have lost the spatial class information necessary to make the map.
For a basic red state/blue state map using ggplot2 and geom_sf(), a manual color palette can be supplied to the scale_fill_manual() function, filling state polygons based on the called column which represents the party for whom the state was called.
ggplot(us_states_joined, aes(fill = called)) +
geom_sf(color = "white", lwd = 0.2) +
scale_fill_manual(values = c("blue", "red")) +
theme_void() +
labs(fill = "Party",
title = " 2020 US presidential election results by state",
caption = "Note: Nebraska and Maine split electoral college votes by congressional district")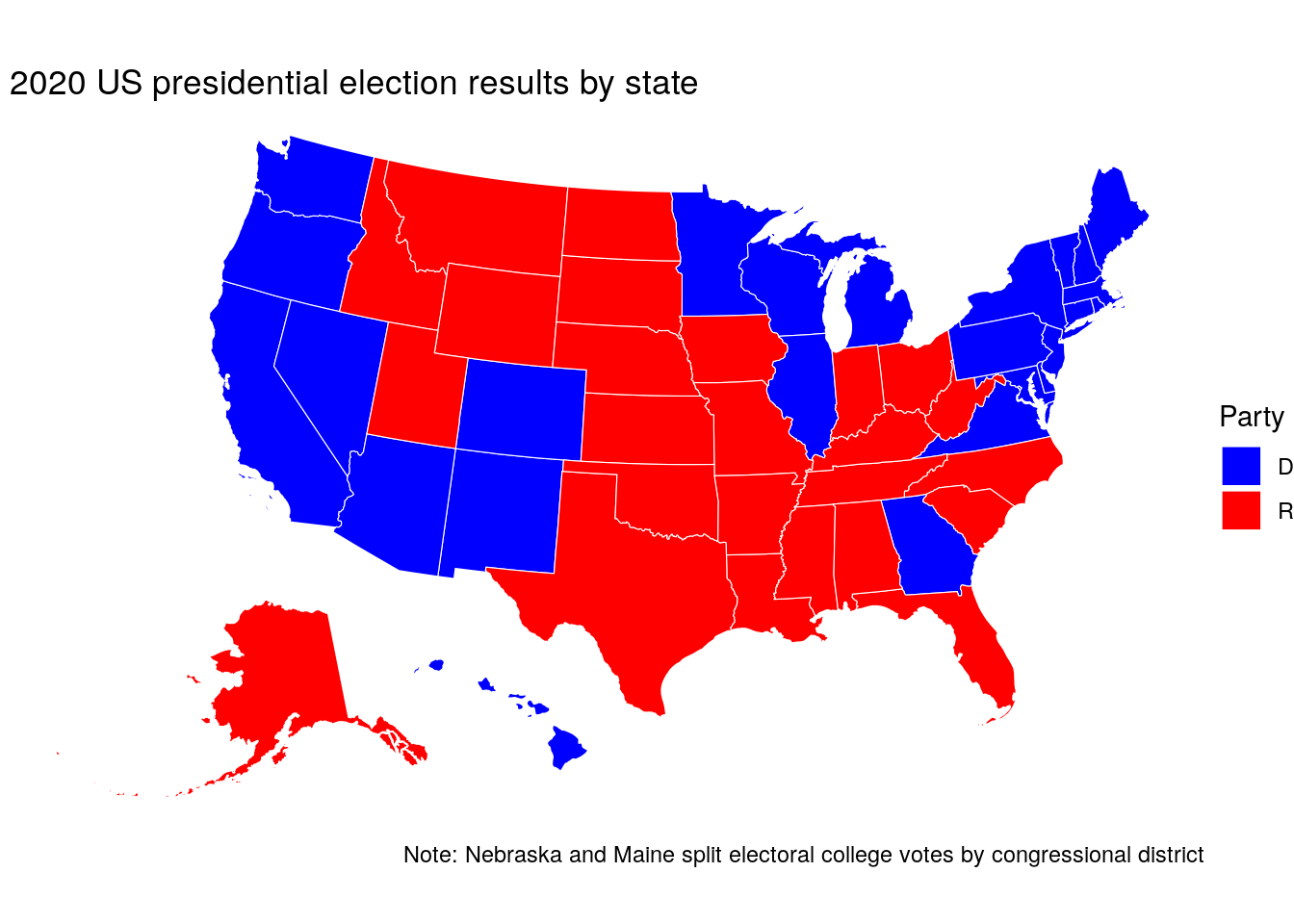
Figure 6.18: Map of the 2020 US presidential election results with ggplot2
6.4.2 Understanding and working with ZCTAs
The most granular geography at which many agencies release data is at the zip code level. This is not an ideal geography for visualization, given that zip codes represent collections of US Postal Service routes (or sometimes even a single building, or Post Office box) that are not guaranteed to form coherent geographies. The US Census Bureau allows for an approximation of zip code mapping with Zip Code Tabulation Areas, or ZCTAs. ZCTAs are shapes built from Census blocks in which the most common zip code for addresses in each block determines how blocks are allocated to corresponding ZCTAs. While ZCTAs are not recommended for spatial analysis due to these irregularities, they can be useful for visualizing data distributions when no other granular geographies are available.
An example of this is the Internal Revenue Service’s Statistics of Income (SOI) data, which includes a wide range of indicators derived from tax returns. The most detailed geography available is the zip code level in this dataset, meaning that within-county visualizations require using ZCTAs. Let’s read in the data for 2018 from the IRS website:
## [1] 153The dataset contains 153 columns which are identified in the linked codebook. Geographies are identified by the ZIPCODE column, which shows aggregated data by state (ZIPCODE == "000000") and by zip code. We might be interested in understanding the geography of self-employment income within a given region. We’ll retain the variables N09400, which represents the number of tax returns with self-employment tax, and N1, which represents the total number of returns.
From here, we’ll need to identify a region of zip codes for analysis. In tigris, the zctas() function allows us to fetch a Zip Code Tabulation Areas shapefile. Given that some ZCTA geography is irregular and sometimes stretches across multiple states, a shapefile for the entire United States must first be downloaded. It is recommended that shapefile caching with options(tigris_use_cache = TRUE) be used with ZCTAs to avoid long data download times.
In the next chapter, you’ll learn how to use spatial overlay to extract geographic data within a specific region. That said, the starts_with parameter in zctas() allows users to filter down ZCTAs based on a vector of prefixes, which can identify an area without using a spatial process. For example, we can get ZCTA data near Boston, MA by using the appropriate prefixes.
library(mapview)
library(tigris)
options(tigris_use_cache = TRUE)
boston_zctas <- zctas(
cb = TRUE,
starts_with = c("021", "022", "024"),
year = 2018
)Next, we can use mapview() to inspect the results:
mapview(boston_zctas)Figure 6.19: ZCTAs in the Boston, MA area
The ZCTA prefixes 021, 022, and 024 cover much of the Boston metropolitan area; “holes” in the region represent areas like Boston Common which are not covered by ZCTAs. Let’s take a quick look at its attributes:
names(boston_zctas)## [1] "ZCTA5CE10" "AFFGEOID10" "GEOID10" "ALAND10" "AWATER10"
## [6] "geometry"Either the ZCTA4CE10 column or the GEOID10 column can be matched to the appropriate zip code information in the IRS dataset for visualization. The code below joins the IRS data to the spatial dataset and computes a new column representing the percentage of returns with self-employment income.
boston_se_data <- boston_zctas %>%
left_join(self_employment, by = c("GEOID10" = "ZIPCODE")) %>%
mutate(pct_self_emp = 100 * (self_emp / total)) %>%
select(GEOID10, self_emp, pct_self_emp)| GEOID10 | self_emp | pct_self_emp | geometry |
|---|---|---|---|
| 02461 | 860 | 24.15730 | MULTIPOLYGON (((-71.22275 4… |
| 02141 | 930 | 11.90781 | MULTIPOLYGON (((-71.09475 4… |
| 02139 | 2820 | 14.58872 | MULTIPOLYGON (((-71.1166 42… |
| 02180 | 1680 | 13.45076 | MULTIPOLYGON (((-71.11976 4… |
| 02457 | NA | NA | MULTIPOLYGON (((-71.27642 4… |
There are a variety of ways to visualize this information. One such method is a choropleth map, which you’ve learned about earlier this chapter:
tm_shape(boston_se_data, projection = 26918) +
tm_fill(col = "pct_self_emp",
palette = "Purples",
title = "% self-employed,\n2018 IRS SOI data")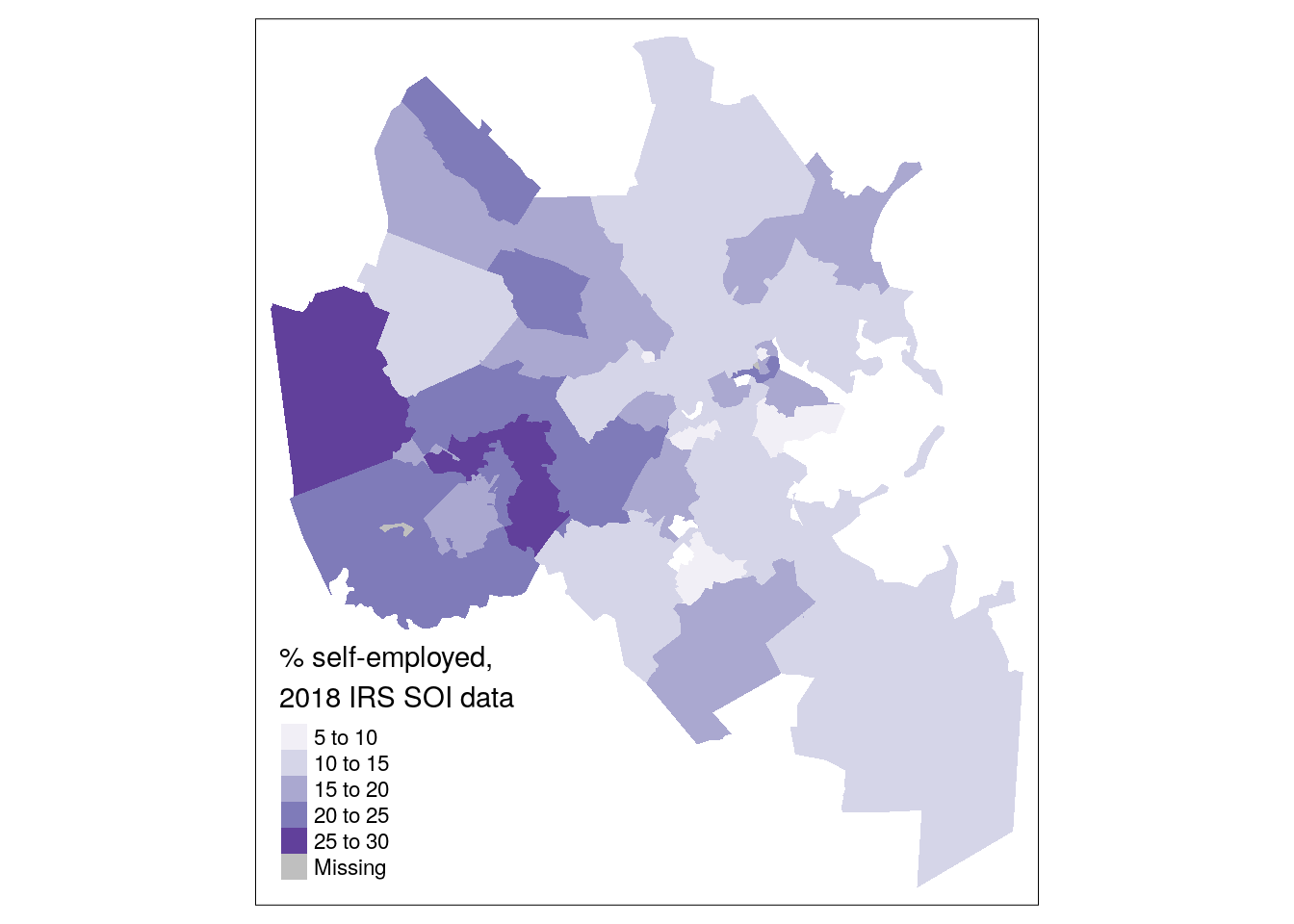
Figure 6.20: Simple choropleth of self-employment in Boston
The choropleth map shows that self-employment filings are more common in suburban Boston ZCTAs than nearer to the urban core, generally speaking. However, we might also be interested in understanding where most self-employment income filings are located rather than their share relative to the total number of returns filed. This requires visualizing the self_emp column directly. As discussed earlier in this chapter, a graduated symbol map with tm_bubbles() is preferable to a choropleth map for this purpose.
tm_shape(boston_se_data) +
tm_polygons() +
tm_bubbles(size = "self_emp",
alpha = 0.5,
col = "navy",
title.size = "Self-employed filers,\n2018 IRS SOI data")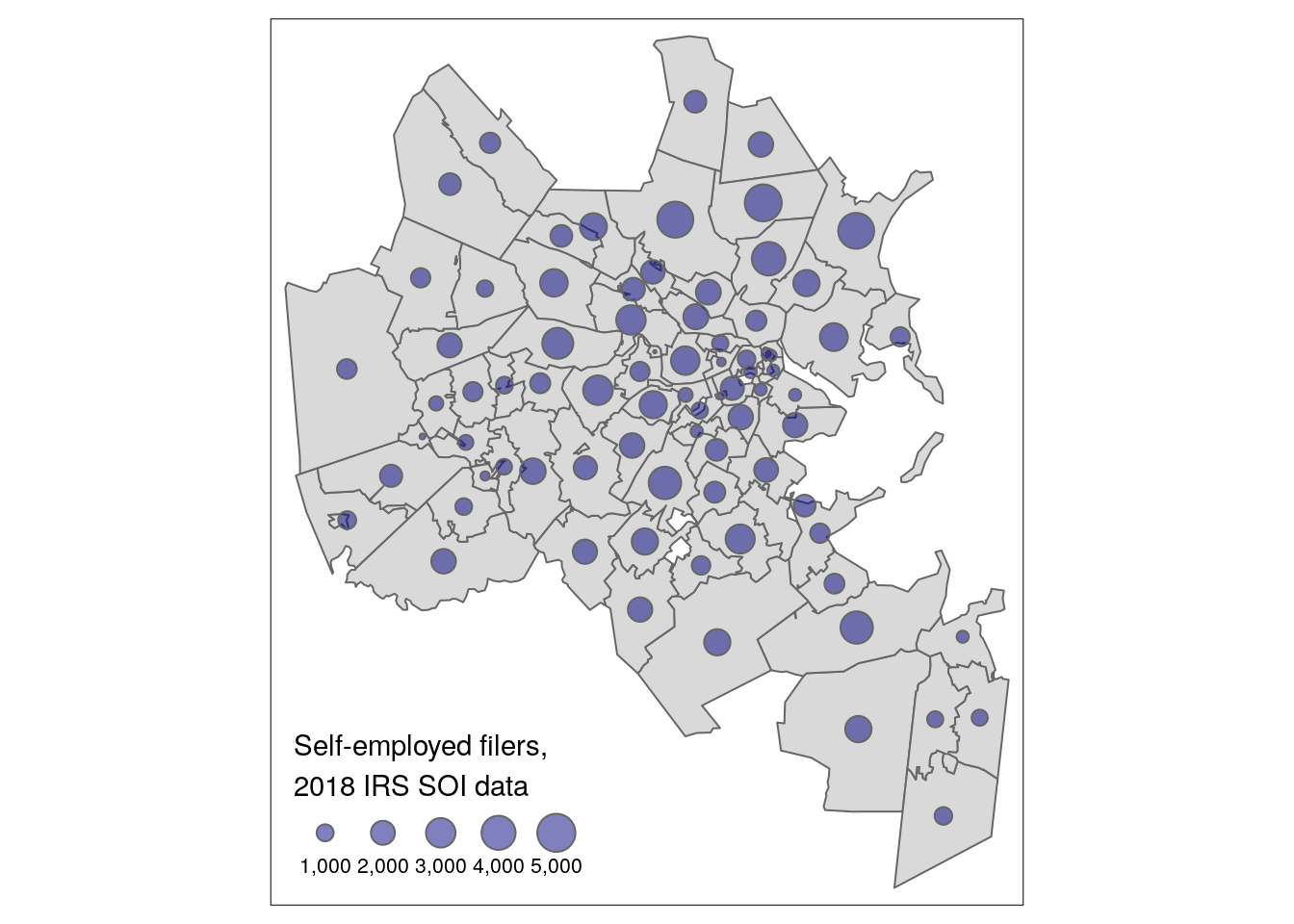
Figure 6.21: Graduated symbol map of self-employment by ZCTA in Boston
6.5 Interactive mapping
The examples addressed in this chapter thus far have all focused on static maps, where the output is fixed after rendering the map. Modern web technologies - and the integration of those technologies into R with the htmlwidgets package, as discussed in Section 4.7.4 - make the creation of interactive, explorable Census data maps straightforward.
6.5.1 Interactive mapping with Leaflet
With over 31,000 GitHub stars as of July 2021, the Leaflet JavaScript library (Agafonkin 2020) is one of the most popular frameworks worldwide for interactive mapping. The RStudio team brought the Leaflet to R with the leaflet R package (Cheng, Karambelkar, and Xie 2021), which now powers several approaches to interactive mapping in R. The following examples cover how to visualize Census data on an interactive Leaflet map using approaches from mapview, tmap, and the core leaflet package.
Let’s start by getting some illustrative data on the percentage of the population aged 25 and up with a bachelor’s degree or higher from the 2016-2020 ACS. We’ll look at this information by Census tract in Dallas County, Texas.
dallas_bachelors <- get_acs(
geography = "tract",
variables = "DP02_0068P",
year = 2020,
state = "TX",
county = "Dallas",
geometry = TRUE
)In Chapter 5, you learned how to quickly visualize geographic data obtained with tigris on an interactive map by using the mapview() function in the mapview package. The mapview() function also includes a parameter zcol that takes a column in the dataset as an argument, and visualizes that column with an interactive choropleth map.
Figure 6.22: Interactive mapview choropleth
Conversion of tmap maps to interactive Leaflet maps is also straightforward with the command tmap_mode("view"). After entering this command, all subsequent tmap maps in your R session will be rendered as interactive Leaflet maps using the same tmap syntax you’d use to make static maps.
library(tmap)
tmap_mode("view")
tm_shape(dallas_bachelors) +
tm_fill(col = "estimate", palette = "magma",
alpha = 0.5)Figure 6.23: Interactive map with tmap in view mode
To switch back to static plotting mode, run the command tmap_mode("plot").
For more fine-grained control over your Leaflet maps, the core leaflet package can be used. Below, we’ll reproduce the mapview/tmap examples using the leaflet package’s native syntax. First, a color palette will be defined using the colorNumeric() function. This function itself creates a function we’re calling pal(), which translates data values to color values for a given color palette. Our chosen color palette in this example is the viridis magma palette.
library(leaflet)
pal <- colorNumeric(
palette = "magma",
domain = dallas_bachelors$estimate
)
pal(c(10, 20, 30, 40, 50))## [1] "#170F3C" "#420F75" "#6E1E81" "#9A2D80" "#C73D73"The map itself is built with a magrittr pipeline and the following steps:
The
leaflet()function initializes the map. Adataobject can be specified here or in a function that comes later in the pipeline.addProviderTiles()helps you add a basemap to the map that will be shown beneath your data as a reference. Several providers are built-in to the Leaflet package, including the popular Stamen reference maps. If you are only interested in a basic basemap, theaddTiles()function returns the standard OpenStreetMap basemap. Use the built-inprovidersobject to try out different basemaps; it is good practice for choropleth mapping to use a greyscale or muted basemap.addPolygons()adds the tract polygons to the map and styles them. In the code below, we are using a series of options to specify the input data; to color the polygons relative to the defined color palette; and to adjust the smoothing between polygon borders, the opacity, and the line weight. Thelabelargument will create a hover tooltip on the map for additional information about the polygons.addLegend()then creates a legend for the map, providing critical information about how the colors on the map relate to the data values.
leaflet() %>%
addProviderTiles(providers$Stamen.TonerLite) %>%
addPolygons(data = dallas_bachelors,
color = ~pal(estimate),
weight = 0.5,
smoothFactor = 0.2,
fillOpacity = 0.5,
label = ~estimate) %>%
addLegend(
position = "bottomright",
pal = pal,
values = dallas_bachelors$estimate,
title = "% with bachelor's<br/>degree"
)Figure 6.24: Interactive leaflet map
This example only scratches the surface of what the leaflet R package can accomplish; I’d encourage you to review the documentation for more examples.
6.5.2 Alternative approaches to interactive mapping
Like most interactive mapping platforms, Leaflet uses tiled mapping in the Web Mercator coordinate reference system. Web Mercator works well for tiled web maps that need to fit within rectangular computer screens, and preserves angles at large scales (zoomed-in areas) which is useful for local navigation. However, it grossly distorts the area of geographic features near the poles, making it inappropriate for small-scale thematic mapping of the world or world regions (Battersby et al. 2014).
Let’s illustrate this by mapping median home value by state from the 1-year ACS using leaflet. We’ll first acquire the data with geometry using tidycensus, setting the output resolution to “20m” to get low-resolution boundaries to speed up our interactive mapping.
us_value <- get_acs(
geography = "state",
variables = "B25077_001",
year = 2019,
survey = "acs1",
geometry = TRUE,
resolution = "20m"
)The acquired ACS data for the US can be mapped using the same techniques as with the educational attainment map for Dallas County.
library(leaflet)
us_pal <- colorNumeric(
palette = "plasma",
domain = us_value$estimate
)
leaflet() %>%
addProviderTiles(providers$Stamen.TonerLite) %>%
addPolygons(data = us_value,
color = ~us_pal(estimate),
weight = 0.5,
smoothFactor = 0.2,
fillOpacity = 0.5,
label = ~estimate) %>%
addLegend(
position = "bottomright",
pal = us_pal,
values = us_value$estimate,
title = "Median home value"
)Figure 6.25: Interactive US map using Web Mercator
The disadvantages of Web Mercator - as well as this general approach to mapping the United States - are on full display. Alaska’s area is grossly distorted relative to the rest of the United States. It is also difficult on this map to compare Alaska and Hawaii to the continental US - which is particularly important in this example as Hawaii’s median home value is the highest in the entire country. The solution proposed elsewhere in this book is to use tigris::shift_geometry() which adopts appropriate coordinate reference systems for Alaska, Hawaii, and the continental US and arranges them in a better comparative fashion on the map. However, this approach risks losing the interactivity of a Leaflet map.
A compromise solution can involve other R packages that allow for interactive mapping. An excellent option is the ggiraph package (Gohel and Skintzos 2021), which like the plotly package can convert ggplot2 graphics into interactive plots. In the example below, interactivity is added to a ggplot2 plot with ggiraph, allowing for panning and zooming with a hover tooltip on a shifted and rescaled map of the US.
library(ggiraph)
library(scales)
us_value_shifted <- us_value %>%
shift_geometry(position = "outside") %>%
mutate(tooltip = paste(NAME, estimate, sep = ": "))
gg <- ggplot(us_value_shifted, aes(fill = estimate)) +
geom_sf_interactive(aes(tooltip = tooltip, data_id = NAME),
size = 0.1) +
scale_fill_viridis_c(option = "plasma", labels = label_dollar()) +
labs(title = "Median housing value by State, 2019",
caption = "Data source: 2019 1-year ACS, US Census Bureau",
fill = "ACS estimate") +
theme_void()
girafe(ggobj = gg) %>%
girafe_options(opts_hover(css = "fill:cyan;"),
opts_zoom(max = 10))Figure 6.26: Interactive US map with ggiraph
6.6 Advanced examples
The examples discussed in this chapter thus far likely cover a large proportion of cartographic use cases for Census data analysts. However, R allows cartographers to go beyond these core map types. This final section of the chapter introduces some options for more advanced visualization using data from tidycensus.
6.6.1 Mapping migration flows
In 2021, tidycensus co-author Matt Herman added support for the ACS Migration Flows API in the package, covered briefly in Section 2.5. One notable feature of this new functionality, available in the get_flows() function, is built-in support for flow mapping with the argument geometry = TRUE. Geometry operates differently for migration flows data given that the geography of interest is not a single location for a given row, but rather the connection between those locations. In turn, for get_flows(), geometry = TRUE returns two POINT geometry columns: one for the location itself, and one for the location to which it is linked.
Let’s take a look for one of the most popular recent migration destinations in the United States: Travis County Texas, home to Austin.
travis_inflow <- get_flows(
geography = "county",
state = "TX",
county = "Travis",
geometry = TRUE
) %>%
filter(variable == "MOVEDIN") %>%
na.omit() %>%
arrange(desc(estimate))| GEOID1 | GEOID2 | FULL1_NAME | FULL2_NAME | variable | estimate | moe | centroid1 | centroid2 |
|---|---|---|---|---|---|---|---|---|
| 48453 | 48491 | Travis County, Texas | Williamson County, Texas | MOVEDIN | 10147 | 1198 | POINT (-97.78195 30.33469) | POINT (-97.60076 30.64804) |
| 48453 | 48201 | Travis County, Texas | Harris County, Texas | MOVEDIN | 5746 | 742 | POINT (-97.78195 30.33469) | POINT (-95.39234 29.85728) |
| 48453 | 48209 | Travis County, Texas | Hays County, Texas | MOVEDIN | 4240 | 839 | POINT (-97.78195 30.33469) | POINT (-98.03107 30.05815) |
| 48453 | 48029 | Travis County, Texas | Bexar County, Texas | MOVEDIN | 3758 | 631 | POINT (-97.78195 30.33469) | POINT (-98.52002 29.44896) |
| 48453 | 48113 | Travis County, Texas | Dallas County, Texas | MOVEDIN | 3005 | 657 | POINT (-97.78195 30.33469) | POINT (-96.77787 32.76663) |
| 48453 | 48439 | Travis County, Texas | Tarrant County, Texas | MOVEDIN | 2053 | 527 | POINT (-97.78195 30.33469) | POINT (-97.29124 32.77156) |
| 48453 | 06037 | Travis County, Texas | Los Angeles County, California | MOVEDIN | 1770 | 426 | POINT (-97.78195 30.33469) | POINT (-118.2339 34.33299) |
| 48453 | 48021 | Travis County, Texas | Bastrop County, Texas | MOVEDIN | 1423 | 334 | POINT (-97.78195 30.33469) | POINT (-97.31201 30.10361) |
| 48453 | 48085 | Travis County, Texas | Collin County, Texas | MOVEDIN | 1172 | 514 | POINT (-97.78195 30.33469) | POINT (-96.57237 33.18791) |
| 48453 | 48141 | Travis County, Texas | El Paso County, Texas | MOVEDIN | 1108 | 445 | POINT (-97.78195 30.33469) | POINT (-106.2348 31.76855) |
The dataset is filtered to focus on in-migration, represented by the MOVEDIN variable, and drops migrations from outside the United States with na.omit() (as these areas do not have a GEOID value).
The mapdeck R package (Cooley 2020) offers excellent support for interactive flow mapping with minimal code. mapdeck is a wrapper of deck.gl, a tremendous visualization library originally developed at Uber that offers 3D mapping capabilities built on top of Mapbox’s GL JS library. Users will need to sign up for a Mapbox account and get a Mapbox access token to use mapdeck; see the mapdeck documentation for more information.
Once set, flow maps can be created by initializing a mapdeck map with mapdeck() then using the add_arc() function, which can link either X/Y coordinate columns or POINT geometry columns, as shown below. In this example, we are using the top 30 origins for migrants to Travis County, and generating a new weight column that makes the proportional arc widths less bulky.
library(mapdeck)
token <- "YOUR TOKEN HERE"
travis_inflow %>%
slice_max(estimate, n = 30) %>%
mutate(weight = estimate / 500) %>%
mapdeck(token = token) %>%
add_arc(origin = "centroid2",
destination = "centroid1",
stroke_width = "weight",
update_view = FALSE) 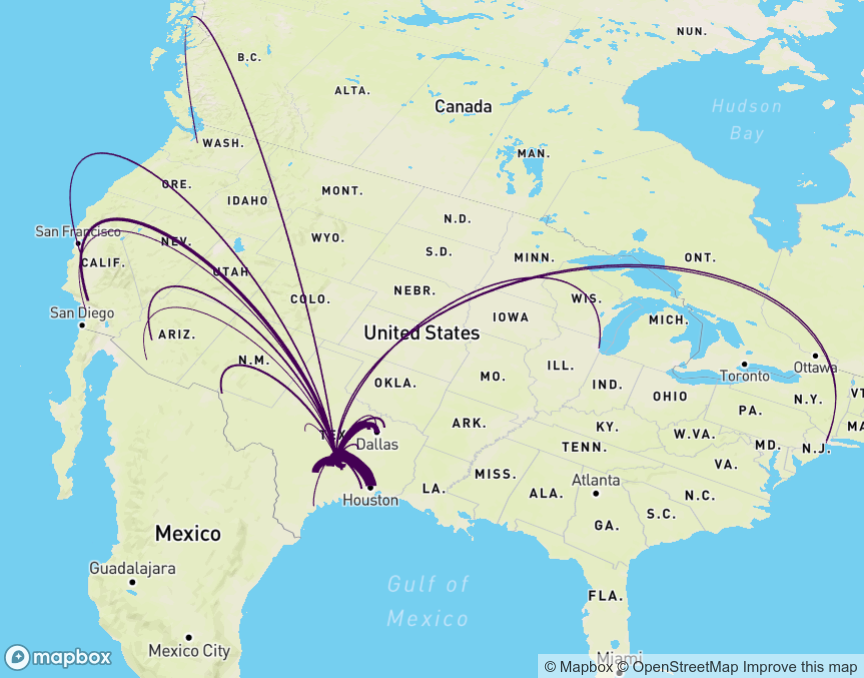
Figure 6.27: Flow map of in-migration to Travis County, TX with mapdeck
6.6.2 Linking maps and charts
This chapter and Chapter 4 are linked in many ways. The visualization principles discussed in each chapter apply to each other; the key difference is that this chapter focuses on geographic visualization whereas Chapter 4 does not. In many cases, you’ll want to take advantage of the strengths of both geographic and non-geographic visualization. Maps are excellent at showing patterns and trends over space, and offer a familiar reference to viewers; charts are better at showing rankings and ordering of data values between places.
The example below illustrates how to combine two chart types discussed in this book: a choropleth map and a margin of error plot. Margins of error are notoriously difficult to display on maps; possible options include superimposing patterns on choropleth maps to highlight areas with high levels of uncertainty (Wong and Sun 2013) or using bivariate choropleth maps to simultaneously visualize estimates and MOEs (Lucchesi and Wikle 2017).
R’s visualization tools offer an alternative approach: interactive linking of a choropleth map with a chart that clearly visualizes the uncertainty around estimates. This approach involves generating a map and chart with ggplot2, then combining the plots with patchwork and rendering them as interactive, linked graphics with ggiraph. The key aesthetic to be used here is data_id, which if set in the code for both plots will highlight corresponding data points on both plots on user hover.
Example code to generate such a linked visualization is below.
library(tidycensus)
library(ggiraph)
library(tidyverse)
library(patchwork)
library(scales)
vt_income <- get_acs(
geography = "county",
variables = "B19013_001",
state = "VT",
year = 2020,
geometry = TRUE
) %>%
mutate(NAME = str_remove(NAME, " County, Vermont"))
vt_map <- ggplot(vt_income, aes(fill = estimate)) +
geom_sf_interactive(aes(data_id = GEOID)) +
scale_fill_distiller(palette = "Greens",
direction = 1,
guide = "none") +
theme_void()
vt_plot <- ggplot(vt_income, aes(x = estimate, y = reorder(NAME, estimate),
fill = estimate)) +
geom_errorbar(aes(xmin = estimate - moe, xmax = estimate + moe)) +
geom_point_interactive(color = "black", size = 4, shape = 21,
aes(data_id = GEOID)) +
scale_fill_distiller(palette = "Greens", direction = 1,
labels = label_dollar()) +
scale_x_continuous(labels = label_dollar()) +
labs(title = "Household income by county in Vermont",
subtitle = "2016-2020 American Community Survey",
y = "",
x = "ACS estimate (bars represent margin of error)",
fill = "ACS estimate") +
theme_minimal(base_size = 14)
girafe(ggobj = vt_map + vt_plot, width_svg = 10, height_svg = 5) %>%
girafe_options(opts_hover(css = "fill:cyan;"))Figure 6.28: Linked map and chart with ggiraph
This example largely re-purposes visualization code readers have learned in other examples in this book. Try hovering your cursor over any county in Vermont on the map - or any data point on the chart - and notice what happens on the other plot. The corresponding county or data point will also be highlighted, allowing for a linked representation of geographic location and margin of error visualization.
6.6.3 Reactive mapping with Shiny
Advanced Census cartographers may want to take these examples a step further and build them into full-fledged data dashboards and web-based visualization applications. Fortunately, R users don’t have to do this from scratch. Shiny (Chang et al. 2021) is a tremendously popular and powerful framework for the development of interactive web applications in R that can execute R code in response to user inputs. A full treatment of Shiny is beyond the scope of this book; however, Shiny is a “must-learn” for R data analysts.
An example Shiny visualization app that extends the race/ethnicity example from this chapter is shown below. It includes a drop-down menu that allows users to select a racial or ethnic group in the Twin Cities and visualizes the distribution of that group on an interactive choropleth map that uses Leaflet and the viridis color palette.
Figure 6.29: Interactive mapping app with Shiny
The code used to create the app is found below; copy-paste this code into your own R script, set your Census API key, and run it! To learn more, I encourage you to review Hadley Wickham’s Mastering Shiny book and the Leaflet package’s documentation on Shiny integration.
# app.R
library(tidycensus)
library(shiny)
library(leaflet)
library(tidyverse)
census_api_key("YOUR KEY HERE")
twin_cities_race <- get_acs(
geography = "tract",
variables = c(
hispanic = "DP05_0071P",
white = "DP05_0077P",
black = "DP05_0078P",
native = "DP05_0079P",
asian = "DP05_0080P",
year = 2019
),
state = "MN",
county = c("Hennepin", "Ramsey", "Anoka", "Washington",
"Dakota", "Carver", "Scott"),
geometry = TRUE
)
groups <- c("Hispanic" = "hispanic",
"White" = "white",
"Black" = "black",
"Native American" = "native",
"Asian" = "asian")
ui <- fluidPage(
sidebarLayout(
sidebarPanel(
selectInput(
inputId = "group",
label = "Select a group to map",
choices = groups
)
),
mainPanel(
leafletOutput("map", height = "600")
)
)
)
server <- function(input, output) {
# Reactive function that filters for the selected group in the drop-down menu
group_to_map <- reactive({
filter(twin_cities_race, variable == input$group)
})
# Initialize the map object, centered on the Minneapolis-St. Paul area
output$map <- renderLeaflet({
leaflet(options = leafletOptions(zoomControl = FALSE)) %>%
addProviderTiles(providers$Stamen.TonerLite) %>%
setView(lng = -93.21,
lat = 44.98,
zoom = 8.5)
})
observeEvent(input$group, {
pal <- colorNumeric("viridis", group_to_map()$estimate)
leafletProxy("map") %>%
clearShapes() %>%
clearControls() %>%
addPolygons(data = group_to_map(),
color = ~pal(estimate),
weight = 0.5,
fillOpacity = 0.5,
smoothFactor = 0.2,
label = ~estimate) %>%
addLegend(
position = "bottomright",
pal = pal,
values = group_to_map()$estimate,
title = "% of population"
)
})
}
shinyApp(ui = ui, server = server)6.7 Working with software outside of R for cartographic projects
The examples shown in this chapter display all maps within R. RStudio users running the code in this chapter, for example, will display static plots in the Plots pane, or interactive maps in the interactive Viewer pane. In many cases, R users will want to export out their maps for display on a website or in a report. In other cases, R users might be interested in using R and tidycensus as a “data pipeline” that can generate appropriate Census data for mapping in an external software package like Tableau, ArcGIS, or QGIS. This section covers those use-cases.
6.7.1 Exporting maps from R
Cartographers exporting maps made with ggplot2 will likely want to use the ggsave() command. The map export process with ggsave() is similar to the process described in Section 4.2.3. If theme_void() is used for the map, however, the cartographer may want to supply a color to the bg parameter, as it would otherwise default to "transparent" for that theme.
The tmap_save() command is the best option for exporting maps made with tmap. tmap_save() requires that a map be stored as an object first; this example will re-use a map of Hennepin County from earlier in the chapter and assign it to a variable named hennepin_map.
hennepin_map <- tm_shape(hennepin_black) +
tm_polygons(col = "percent",
style = "jenks",
n = 5,
palette = "Purples",
title = "ACS estimate",
legend.hist = TRUE) +
tm_layout(title = "Percent Black\nby Census tract",
frame = FALSE,
legend.outside = TRUE,
bg.color = "grey70",
legend.hist.width = 5,
fontfamily = "Verdana")That map can be saved using similar options to ggsave(). tmap_save() allows for specification of width, height, units, and dpi. If small values are passed to width and height, tmap will assume that the units are inches; if large values are passed (greater than 50), tmap will assume that the units represent pixels.
tmap_save(
tm = hennepin_map,
filename = "~/images/hennepin_black_map.png",
height = 5.5,
width = 8,
dpi = 300
)Interactive maps designed with leaflet can be written to HTML documents using the saveWidget() function from the htmlwidgets package. A Leaflet map should first be assigned to a variable, which is then passed to saveWidget() along with a specified name and path for the output HTML file. Interactive maps created with mapview() are written to HTML files the same way, though the object to be saved will need to be accessed from the map slot with the notation @map, as shown below.
library(htmlwidgets)
dallas_map <- mapview(dallas_bachelors, zcol = "estimate")
saveWidget(dallas_map@map, "dallas_mapview_map.html", selfcontained = TRUE)The argument selfcontained = TRUE is an important one to consider when writing interactive maps to HTML files. If TRUE as shown in the example, saveWidget() will bundle any necessary assets (e.g. CSS, JavaScript) as a base64-encoded string in the HTML file. This makes the HTML file more portable but can lead to large file sizes. The alternative, selfcontained = FALSE, places these assets into an accompanying directory when the HTML file is written out. For interactive maps generated with tmap, tmap_save() can also be used to write out HTML files in this way.
6.7.2 Interoperability with other visualization software
Although R packages have rich capabilities for designing both static and interactive maps as well as map-based dashboards, some analysts will want to turn to other specialized tools for data visualization. Such tools might include drag-and-drop dashboard builders like Tableau, or dedicated GIS software like ArcGIS or QGIS that allow for more manual control over cartographic layouts and outputs.
This workflow will often involve the use of R, and packages like tidycensus, for data acquisition and wrangling, then the use of an external visualization program for data visualization and cartography. In this workflow, an R object produced with tidycensus can be written to an external spatial file with the st_write() function in the sf package. The code below illustrates how to write Census data from R to a shapefile, a common vector spatial data format readable by desktop GIS software and Tableau.
library(tidycensus)
library(sf)
options(tigris_use_cache = TRUE)
dc_income <- get_acs(
geography = "tract",
variables = "B19013_001",
state = "DC",
year = 2020,
geometry = TRUE
)
st_write(dc_income, "dc_income.shp")The output file dc_income.shp will be written to the user’s current working directory. Other spatial data formats like GeoPackage (.gpkg) and GeoJSON (.geojson) are available by specifying the appropriate file extension.
QGIS cartographers can also take advantage of functionality within the software to run R (and consequently tidycensus functions) directly within the platform. In QGIS, this is enabled with the Processing R Provider plugin. QGIS users should install the plugin from the Plugins drop-down menu, then click Processing > Toolbox to access QGIS’s suite of tools. Clicking the R icon then Create New R Script… will open the R script editor.
The example script below will be translated by QGIS into a GIS tool that uses the version of tidycensus installed on a user’s system to add a demographic layer at the Census tract level from the ACS to a QGIS project.
##Variable=string
##State=string
##County=string
##Output=output vector
library(tidycensus)
Output = get_acs(
geography = "tract",
variables = Variable,
state = State,
county = County,
geometry = TRUE
)Tool parameters are defined at the beginning of the script with ## notation. Variable, State, and County will all accept strings (text) as input, and the result of get_acs() in the tool will be written to Output, which is added to the QGIS project as a vector layer. Once finished, the script should be saved with an appropriate name and the file extension .rsx in the suggested output directory, then located from the R section of the Processing Toolbox and opened. The GIS tool will look something like the image below.
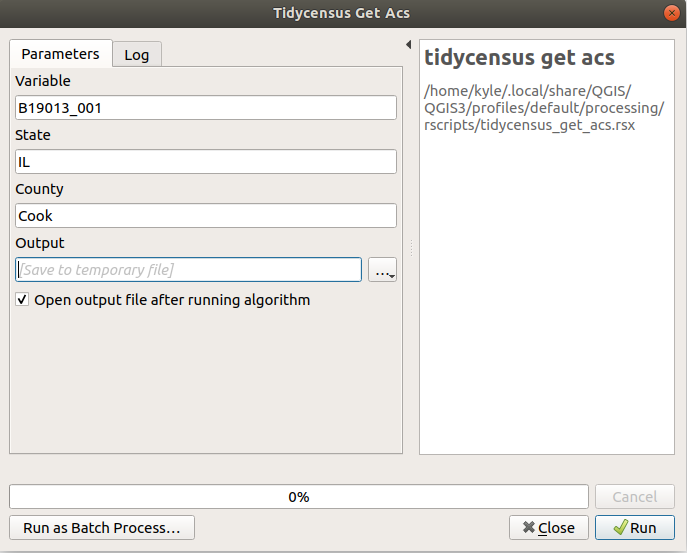
Figure 6.30: Example tidycensus tool in QGIS
Fill in the text boxes with a desired ACS variable, state, and county, then click Run. The QGIS tool will call the user’s R installation to execute the tool with the specified inputs. If everything runs correctly, a layer will be added to the user’s QGIS project ready for mapping with QGIS’s suite of cartographic tools.
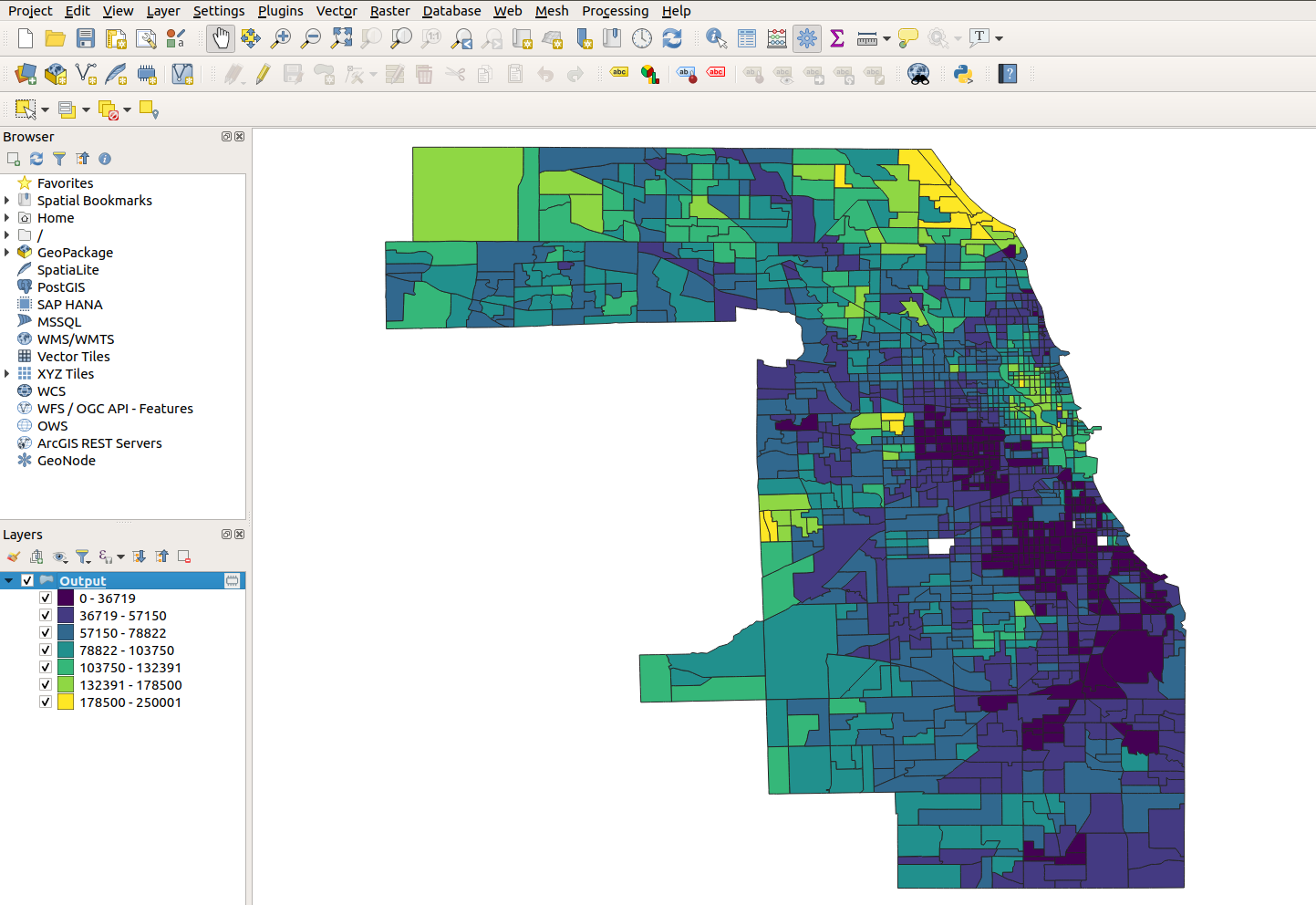
Figure 6.31: Styled layer from tidycensus in QGIS
The example shown displays Census tracts in Cook County, Illinois obtained from tidycensus in a QGIS project; these tracts have been styled as a choropleth in QGIS by median household income (the requested variable) after the tool added the layer to the project.
6.8 Exercises
Using one of the mapping frameworks introduced in this chapter (either ggplot2, tmap, or leaflet) complete the following tasks:
If you are just getting started with tidycensus/the tidyverse, make a race/ethnicity map by adapting the code provided in this section but for a different county.
Next, find a different variable to map with
tidycensus::load_variables(). Review the discussion of cartographic choices in this chapter and visualize your data appropriately.