11 Other Census and government data resources
Most of the examples covered in the book to this point use data from recent US Census Bureau datasets such as the Decennial Census since 2000 and the American Community Survey. These datasets are available through the US Census Bureau’s APIs and in turn accessible with tidycensus and related tools. However, analysts and historians may be interested in accessing data from much earlier - perhaps all the way back to 1790, the first US Census! Fortunately, these historical datasets are available to analysts through the National Historical Geographic Information System (NHGIS) project and the Minnesota Population Center’s IPUMS project. While both of these data repositories have typically attracted researchers using commercial software such as ArcGIS (for NHGIS) and Stata/SAS (for IPUMS), the Minnesota Population Center has developed an associated ipumsr R package to help analysts integrate these datasets into R-based workflows.
Additionally, the US Census Bureau publishes many other surveys and datasets besides the decennial US Census and American Community Survey. While tidycensus focuses on these core datasets, other R packages provide support for the wide range of datasets available from the Census Bureau and other government agencies.
The first part of this chapter provides an overview of how to access and use historical US Census datasets in R with NHGIS, IPUMS, and the ipumsr package. Due to the size of the datasets involved, these datasets are not provided with the sample data available in the book’s data repository. To reproduce, readers should follow the steps provided to sign up for an IPUMS account and download the data themselves. The second part of this chapter covers R workflows for Census data resources outside the decennial US Census and American Community Survey. It highlights packages such as censusapi, which allows for programmatic access to all US Census Bureau APIs, and lehdr, which grants access to the LEHD LODES dataset for analyzing commuting flows and jobs distributions. Other government data resources are also addressed at the end of the chapter.
11.1 Mapping historical geographies of New York City with NHGIS
The National Historical Geographic Information System (NHGIS) project (Manson et al. 2021) is a tremendous resource for both contemporary and historical US Census data. While some datasets (e.g. the 2000 and 2010 decennial US Censuses, the ACS) can be accessed with both tidycensus and NHGIS, NHGIS is an excellent option for users who prefer browsing data menus to request data and/or who require historical information earlier than 2000. The example in this section will illustrate an applied workflow using NHGIS and its companion R package, ipumsr (Ellis and Burk 2020) to map geographies of immigration in New York City from the 1910 Census.
11.1.1 Getting started with NHGIS
To get started with NHGIS, visit the NHGIS website and click the “REGISTER” link at the top of the screen to register for an account. NHGIS asks for some basic information about your work and how you plan to use the data, and you’ll agree to the NHGIS usage license agreement. Once registered, return to the NHGIS home page and click the “Get Data” button to visit the NHGIS data browser interface.
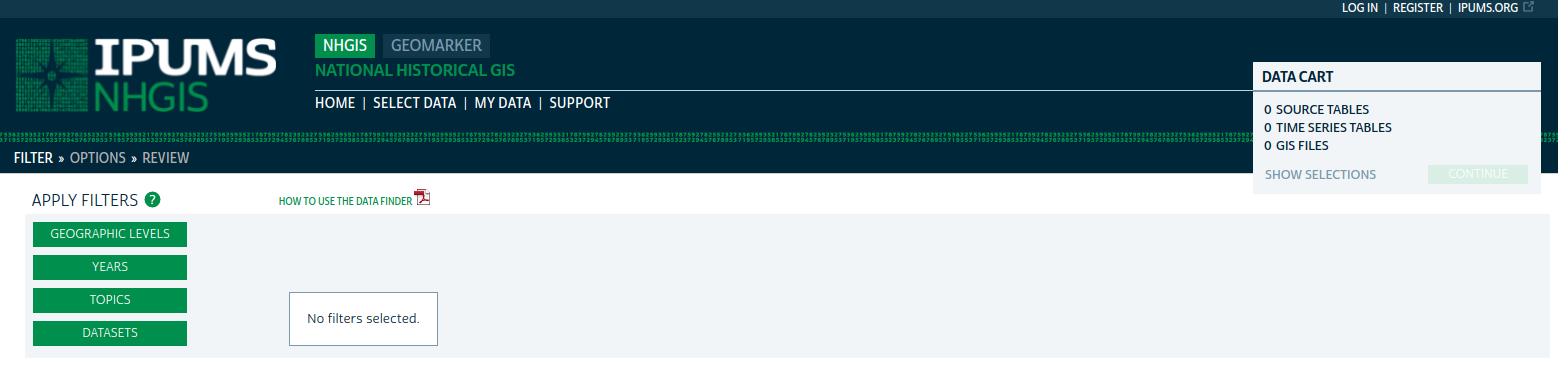
Figure 11.1: NHGIS data browser interface
A series of options on the left-hand side of your screen. These options include:
Geographic levels: the level of aggregation for your data. NHGIS includes a series of filters to help you choose the correct level of aggregation; click the plus sign to select it. Keep in mind that not all geographic levels will be available for all variables and all years. To reproduce the example in this section, click “CENSUS TRACT” then “SUBMIT.”
Years: The year(s) for which you would like to request data. Decennial, non-decennial, and 5-year ranges are available for Census tracts. Note that many years are greyed out - this means that no data are available for those years at the Census tract level. The earliest year for which Census tract-level data are available is 1910, which is the year we will choose; check the box next to “1910” then click SUBMIT.
Topics: This menu helps you filter down to specific areas of interest in which you are searching for data to select. Data are organized into categories (e.g. race, ethnicity, and origins) and sub-topics (e.g. age, sex). Topics not available at your chosen geography/year combination are greyed out. Choose the “Nativity and Place of Birth” topic then click SUBMIT.
Datasets: The specific datasets from which you would like to request data, which is particularly useful when there are multiple datasets available in a given year. In this applied example, there is only one dataset that aligns with our choices: Population Data for Census tracts in New York City in 1910. As such, there is no need to select anything here.
The Select Data menu shows which Census tables are available given your filter selections. Usefully, the menu includes embedded links that give additional information about the available data choices, along with a “popularity” bar graph showing the most-downloaded tables for that particular dataset.
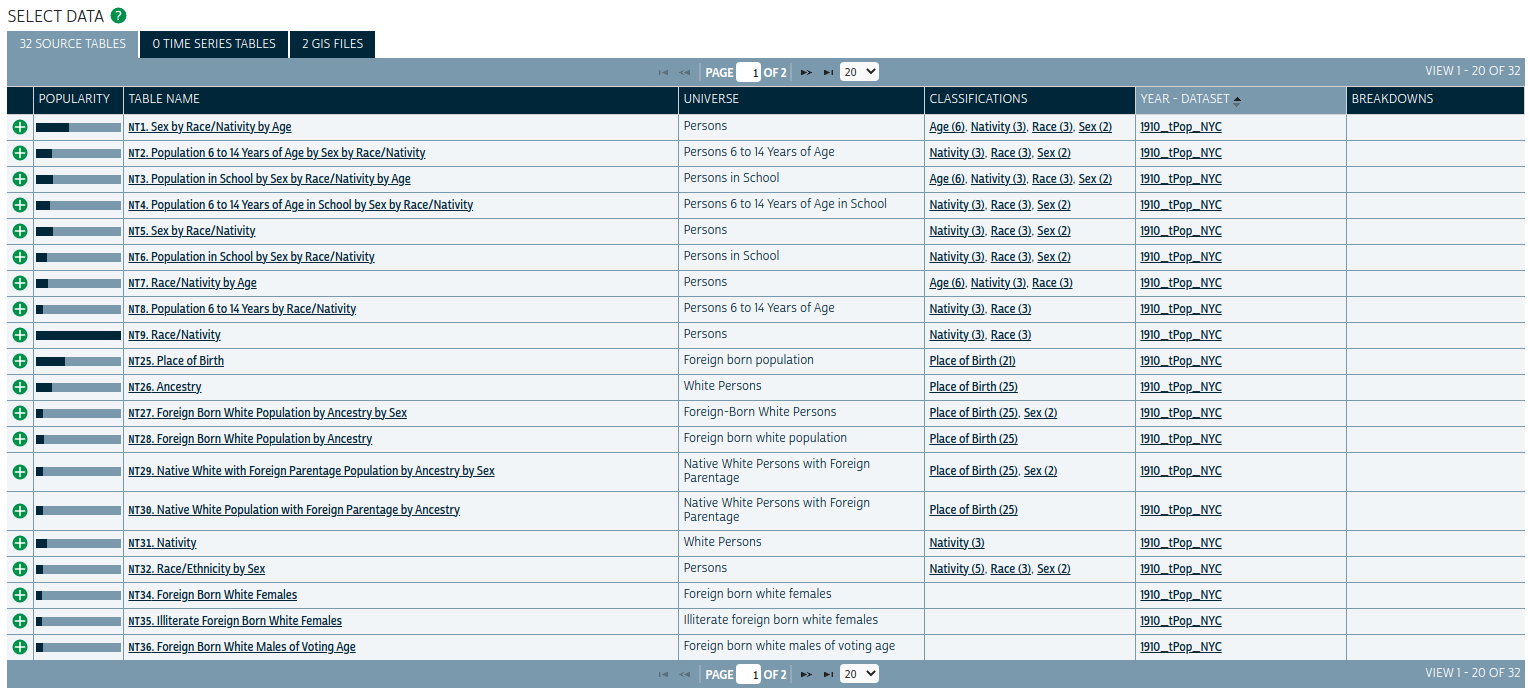
Figure 11.2: NHGIS Select Data screen
For this example, choose the tables “NT26: Ancestry” and “NT45: Race/Ethnicity” by clicking the green plus signs next to the two to select them. Then, click the GIS FILES tab. This tab allows you to select companion shapefiles that can be merged to the demographic extracts for mapping in a desktop GIS or in software like R. Choose either of the Census Tract options then click “CONTINUE” to review your selection. On the “REVIEW AND SUBMIT” screen, keep the “Comma delimited” file structure selected and give your extract a description if you would like.
When finished, click SUBMIT. You’ll be taken to the “EXTRACTS HISTORY” screen where you can download your data when it is ready; you’ll receive a notification by email when your data can be downloaded. Once you receive this notification, return to NHGIS and download both the table data and the GIS data to the same directory on your computer.
11.1.2 Working with NHGIS data in R
Once acquired, NHGIS spatial and attribute data can be integrated seamlessly into R-based data analysis workflows thanks to the ipumsr package. ipumsr includes a series of NHGIS-specific functions: read_nhgis(), which reads in the tabular aggregate data; read_nhgis_sf(), which reads in the spatial data as a simple features object; and read_nhgis_sp(), which reads in the spatial data in legacy sp format.
read_nhgis_sf() has built-in features to make working with spatial and demographic data simpler for R users. If the data_file argument is pointed to the CSV file with the demographic data, and the shape_file argument is pointed to the shapefile, read_nhgis_sf() will read in both files simultaneously and join them correctly based on a common GISJOIN column found in both files. An additional perk is that read_nhgis_sf() can handle the zipped folders, removing an additional step from the analyst’s data preparation workflow.
The example below uses read_nhgis_sf() to read in spatial and demographic data on immigrants in New York City in 1910. As the 1910 shapefile folder includes both NYC Census tracts and a separate dataset with US counties, the top-level folder should be unzipped, shape_file pointed to the second-level zipped folder, and the shape_layer argument used to exclusively read in the tracts. The filter() call will drop Census tracts that do not have corresponding data (so, outside NYC).
library(ipumsr)
library(tidyverse)
# Note: the NHGIS file name depends on a download number
# that is unique to each user, so your file names will be
# different from the code below
nyc_1910 <- read_nhgis_sf(
data_file = "data/NHGIS/nhgis0099_csv.zip",
shape_file = "data/NHGIS/nhgis0099_shape/nhgis0099_shapefile_tl2000_us_tract_1910.zip",
shape_layer = starts_with("US_tract_1910")
) %>%
filter(str_detect(GISJOIN, "G36"))## Use of data from NHGIS is subject to conditions including that users should
## cite the data appropriately. Use command `ipums_conditions()` for more details.
##
##
## Reading data file...
## Reading geography...
## options: ENCODING=latin1
## Reading layer `US_tract_1910' from data source
## `/tmp/RtmpnGmGn8/file78ab77cac966/US_tract_1910.shp' using driver `ESRI Shapefile'
## Simple feature collection with 1989 features and 6 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: 489737.4 ymin: 130629.6 xmax: 2029575 ymax: 816129.7
## Projected CRS: USA_Contiguous_Albers_Equal_Area_Conicread_nhgis_sf() has read in the tracts shapefile as a simple features object then joined the corresponding CSV file to it and imported data labels from the data codebook. Note that if you are reproducing this example with data downloaded yourself, you will have a unique zipped folder & file name based on your unique download ID. The “99” in the example above reflects the 99th extract from NHGIS for a given user, not a unique dataset name.
The best way to review the variables and their labels is the View() command in RStudio, which is most efficient on sf objects when the geometry is first dropped with sf::st_drop_geometry().
View(sf::st_drop_geometry(nyc_1910))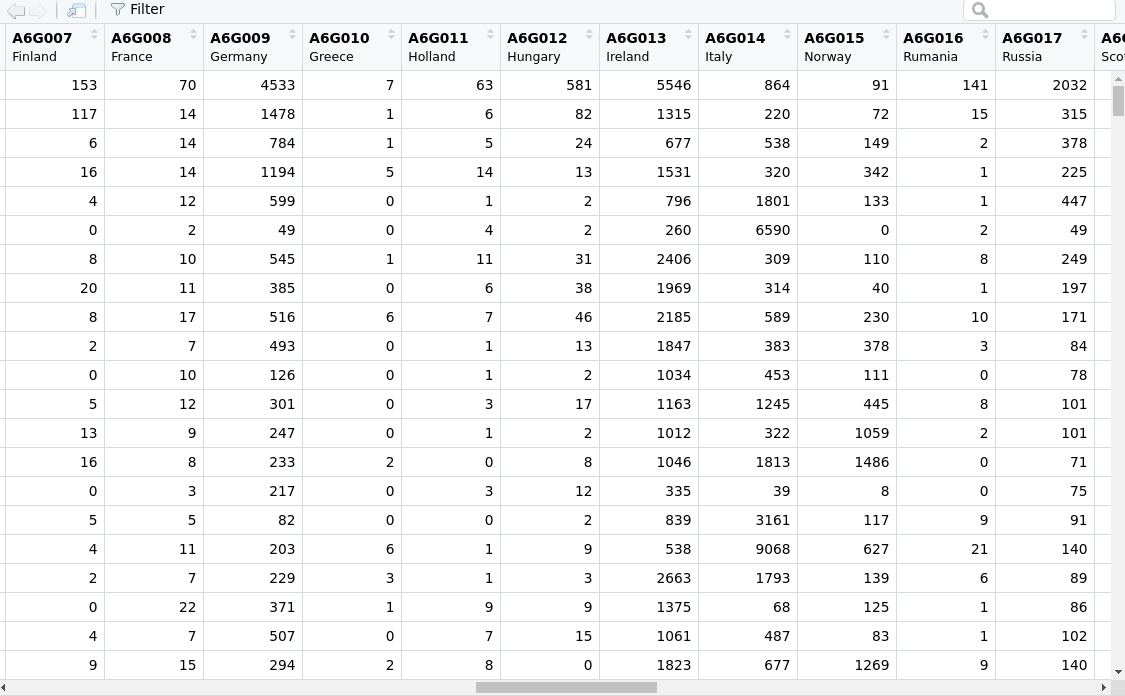
Figure 11.3: NHGIS data in the RStudio Viewer
As shown in the graphic above, the variable labels are particularly useful when using View() to understand what the different variables mean without having to reference the codebook.
11.1.3 Mapping NHGIS data in R
The message displayed when reading in the NHGIS shapefile above indicates that the Census tract data are in a projected coordinate reference system, USA_Contiguous_Albers_Equal_Area_Conic. The spatial data can be displayed with plot():
plot(nyc_1910$geometry)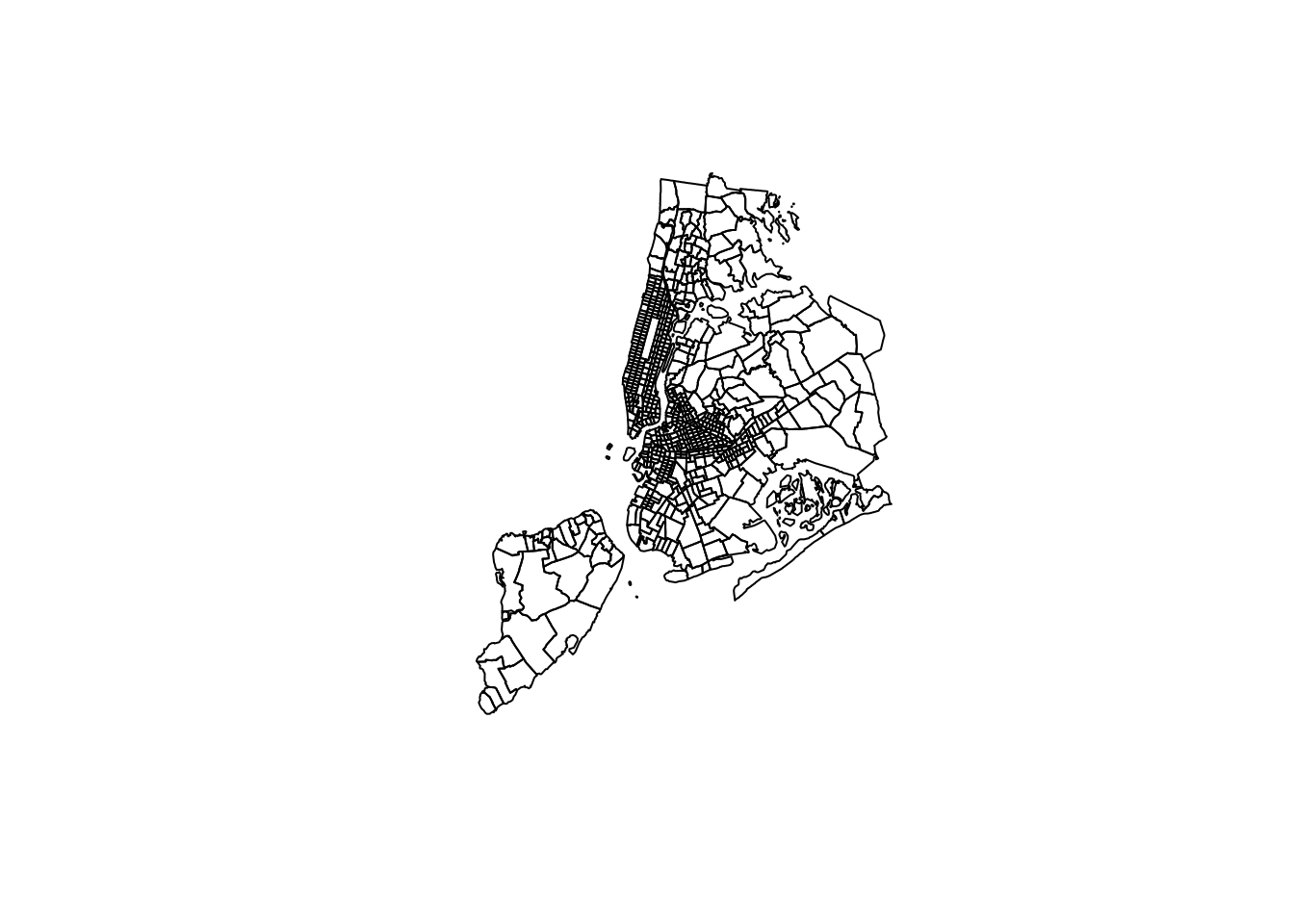
Figure 11.4: Plot of NYC Census tracts in 1910 using an Albers Equal Area CRS
The data reflect Census tracts for New York City, but appear rotated counter-clockwise. This is because the coordinate reference system used, ESRI:100023, is appropriate for the entire United States (in fact, it is the base CRS used for tigris::shift_geometry()), but will not be appropriate for any specific small area. As covered in Chapter 5, the crsuggest package helps identify more appropriate projected coordinate reference system options.
library(crsuggest)
library(sf)
suggest_crs(nyc_1910)| crs_code | crs_name | crs_type | crs_gcs | crs_units |
|---|---|---|---|---|
| 6539 | NAD83(2011) / New York Long Island (ftUS) | projected | 6318 | us-ft |
| 6538 | NAD83(2011) / New York Long Island | projected | 6318 | m |
| 4456 | NAD27 / New York Long Island | projected | 4267 | us-ft |
| 3628 | NAD83(NSRS2007) / New York Long Island (ftUS) | projected | 4759 | us-ft |
| 3627 | NAD83(NSRS2007) / New York Long Island | projected | 4759 | m |
| 32118 | NAD83 / New York Long Island | projected | 4269 | m |
| 2908 | NAD83(HARN) / New York Long Island (ftUS) | projected | 4152 | us-ft |
| 2831 | NAD83(HARN) / New York Long Island | projected | 4152 | m |
| 2263 | NAD83 / New York Long Island (ftUS) | projected | 4269 | us-ft |
| 3748 | NAD83(HARN) / UTM zone 18N | projected | 4152 | m |
Based on these suggestions, we’ll select the CRS “NAD83(2011) / New York Long Island” which has an EPSG code of 6538.
nyc_1910_proj <- st_transform(nyc_1910, 6538)
plot(nyc_1910_proj$geometry)
Figure 11.5: NYC Census tracts with an area-appropriate CRS
Given the information in the two tables downloaded from NHGIS, there are multiple ways to visualize the demographics of New York City in 1910. The first example is a choropleth map of the percentage of the total population born outside the United States. As there is no “total population” column in the dataset, the code below uses dplyr’s rowwise() and c_across() functions to perform row-wise calculations and sum across the columns A60001 through A60007. The transmute() function then works like a combination of mutate() and select(): it calculates two new columns, then selects only those columns in the output dataset nyc_pctfb.
nyc_pctfb <- nyc_1910_proj %>%
rowwise() %>%
mutate(total = sum(c_across(A60001:A60007))) %>%
ungroup() %>%
transmute(
tract_id = GISJOIN,
pct_fb = A60005 / total
) The result can be visualized with any of the mapping packages covered in Chapter 6, such as ggplot2 and geom_sf().
ggplot(nyc_pctfb, aes(fill = pct_fb)) +
geom_sf(color = NA) +
scale_fill_viridis_c(option = "rocket", labels = scales::percent, direction = -1) +
theme_void(base_family = "Verdana") +
labs(title = "Percent foreign-born by Census tract, 1910",
subtitle = "New York City",
caption = "Data source: NHGIS",
fill = "Percentage")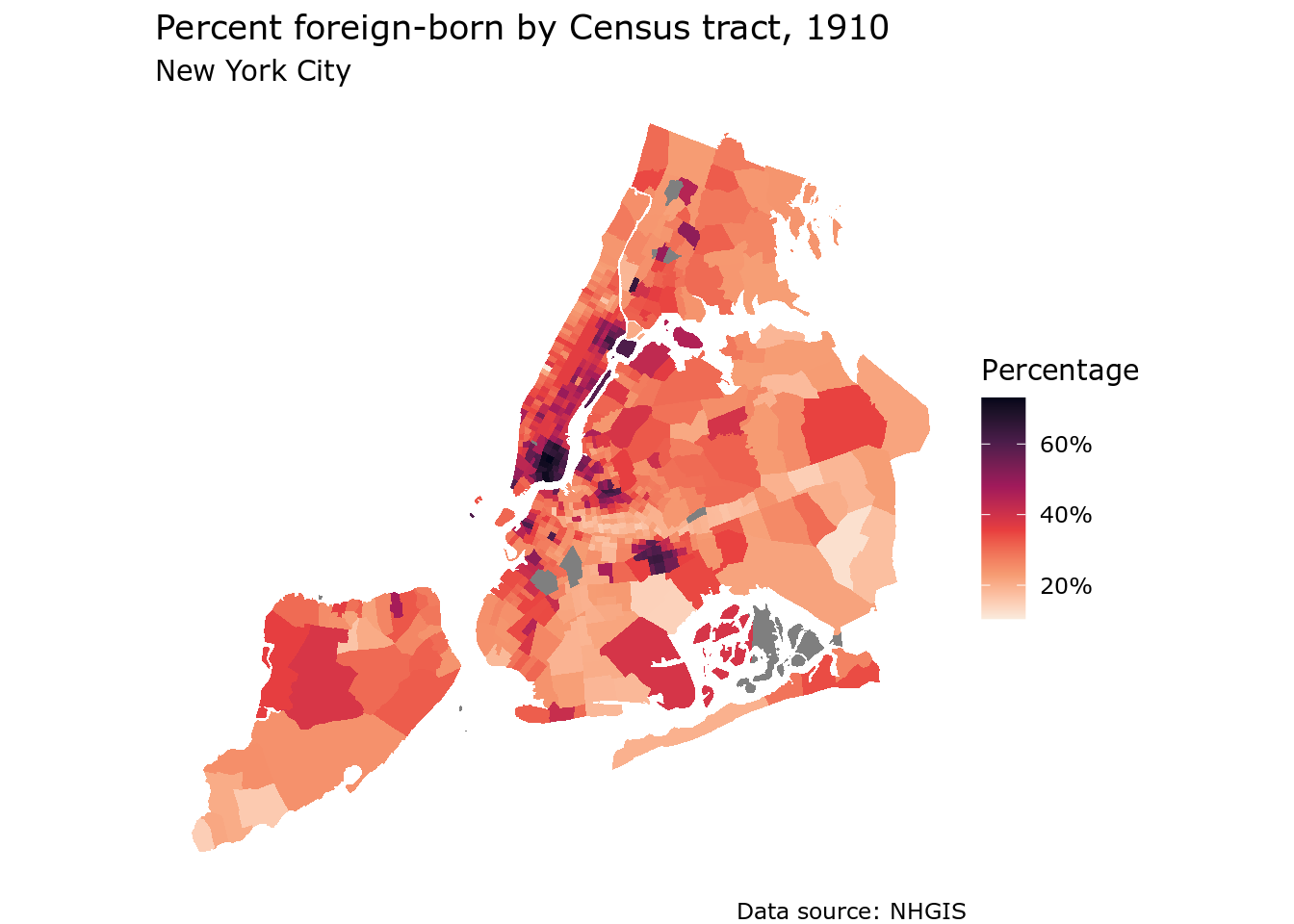
Figure 11.6: Percent foreign-born by Census tract in NYC in 1910, mapped with ggplot2
Manhattan’s Lower East Side stands out as the part of the city with the largest proportion of foreign-born residents in 1910, with percentages exceeding 60%.
An alternative view could focus on one of the specific groups represented in the columns in the dataset. For example, the number of Italy-born residents by Census tract is represented in the column A6G014; this type of information could be represented by either a graduated symbol map or a dot-density map. Using techniques learned in Section 6.3.4.3, we can use the as_dot_density() function in the tidycensus package to generate one dot for approximately every 100 Italian immigrants. Next, the Census tracts are dissolved with the st_union() function to generate a base layer on top of which the dots will be plotted.
library(tidycensus)
italy_dots <- nyc_1910_proj %>%
as_dot_density(
value = "A6G014",
values_per_dot = 100
)
nyc_base <- nyc_1910_proj %>%
st_union()In Section 6.3.4.3, we used tmap::tm_dots() to create a dot-density map. ggplot2 and geom_sf() also work well for dot-density mapping; cartographers can either use geom_sf() with a very small size argument, or set shape = "." where each data point will be represented by a single pixel on the screen.
ggplot() +
geom_sf(data = nyc_base, size = 0.1) +
geom_sf(data = italy_dots, shape = ".", color = "darkgreen") +
theme_void(base_family = "Verdana") +
labs(title = "Italy-born population in New York City, 1910",
subtitle = "1 dot = 100 people",
caption = "Data source: NHGIS")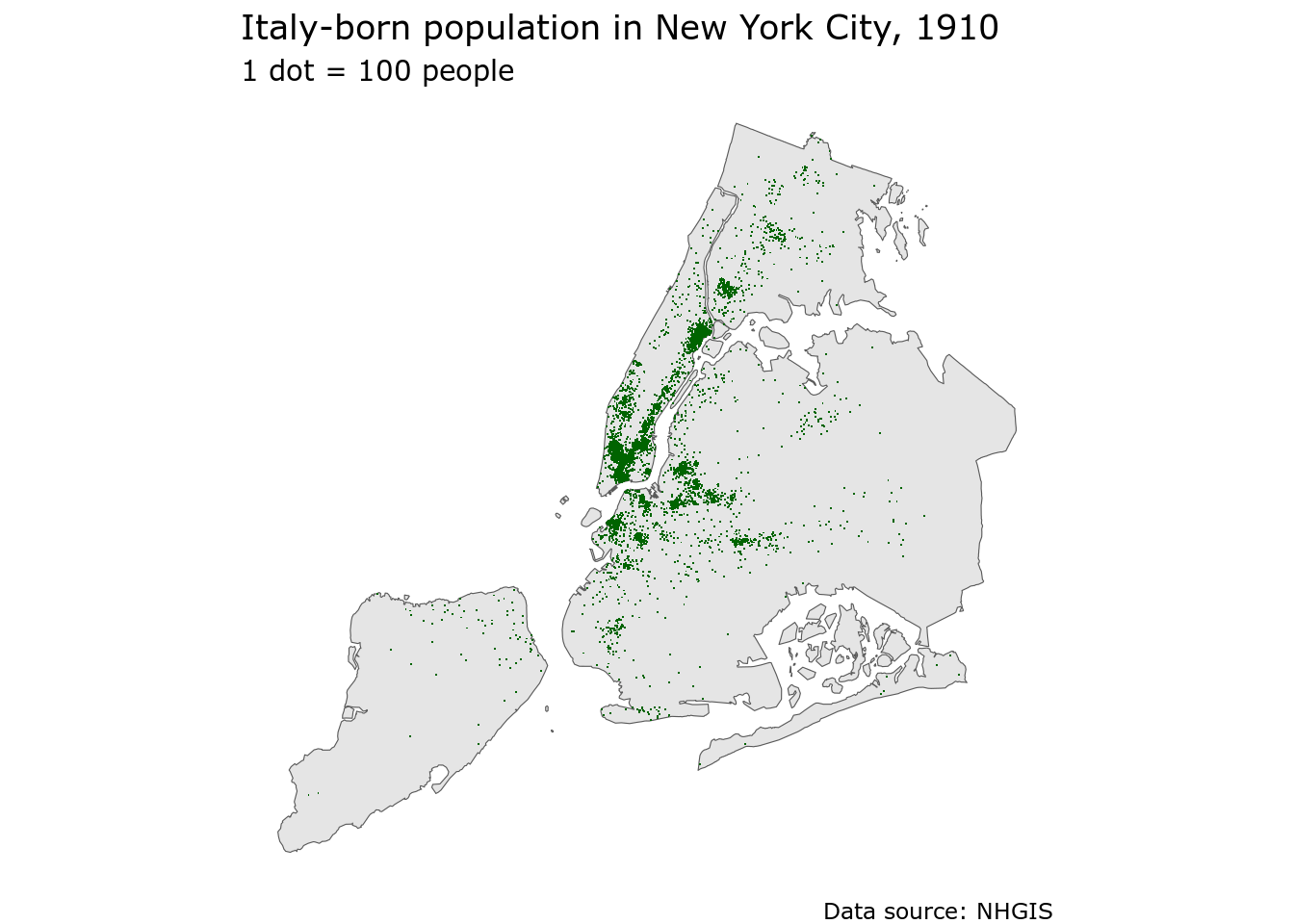
Figure 11.7: Dot-density map of the Italy-born population in NYC in 1910, mapped with ggplot2
The resulting map highlights areas with large concentrations of Italian immigrants in New York City in 1910.
11.2 Analyzing complete-count historical microdata with IPUMS and R
Chapters 9 and 10 covered the process of acquiring and analyzing microdata from the American Community Survey with tidycensus. As noted, these workflows are only available for recent demographics, reflecting the recent availability of the ACS. Historical researchers will need data that goes further back, and will likely turn to IPUMS-USA for these datasets. IPUMS-USA makes available microdata samples all the way back to 1790, enabling historical demographic research not possible elsewhere.
A core focus of Chapter 10 was the use of sampling weights to appropriately analyze and model microdata. Historical Census datasets, however, are subject to the “72-year rule”, which states:
The U.S. government will not release personally identifiable information about an individual to any other individual or agency until 72 years after it was collected for the decennial census. This “72-Year Rule” (92 Stat. 915; Public Law 95-416; October 5, 1978) restricts access to decennial census records to all but the individual named on the record or their legal heir.
This means that decennial Census records that reflect periods 72 years ago or older can be made available to researchers by the IPUMS team. In fact, complete-count Census microdata can be downloaded from IPUMS at the person-level for the Census years 1850-1940, and at the household level for years earlier than 1850.
The availability of complete-count Census records offers a tremendous analytic opportunity for researchers, but also comes with some challenges. The largest ACS microdata sample - the 2016-2020 5-year ACS - has around 16 million records, which can be read into memory on a standard desktop computer with 16GB RAM. Complete-count Census data can have records exceeding 100 million, which will not be possible to read into memory in R on a standard computer. This chapter covers R-based workflows for handling massive Census microdata without needing to upgrade one’s computer or set up a cloud computing instance. The solution presented involves setting up a local database with PostgreSQL and the DBeaver platform, then interacting with microdata in that database using R’s tidyverse and database interface tooling.
11.2.1 Getting microdata from IPUMS
To get started, visit the IPUMS-USA website at https://usa.ipums.org/usa/. If you already signed up for an IPUMS account in Section 11.1.1, log in with your user name and password; otherwise follow those instructions to register for an account, which you can use for all of the IPUMS resources including NHGIS. Once you are logged in, click the “Get Data” button to visit the data selection menu.
Figure 11.8: IPUMS data browser
You’ll use the various options displayed in the image above to define your extract. These options include:
Select samples: choose one or more data samples to include in your microdata extract. You can choose a wide range of American Community Survey and Decennial US Census samples, or you can download full count Census data from the “USA FULL COUNT” tab. To reproduce this example, choose the 1910 100% dataset by first un-checking the “Default sample from each year” box, clicking the “USA FULL COUNT” tab, then choosing the 1910 dataset and clicking SUBMIT SAMPLE SELECTIONS.
Select harmonized variables: One of the major benefits of using IPUMS for microdata analysis is that the IPUMS team has produced harmonized variables that aim to reconcile variable IDs and variable definitions over time allowing for easier longitudinal analysis. By default, users will browse and select from these harmonized variables. Choose from household-level variables and person-level variables by browsing the drop-down menus and selecting appropriate variable IDs; these will be added to your output extract. For users who want to work with variables as they originally were in the source dataset, click the SOURCE VARIABLES radio button to switch to source variables. To replicate this example, choose the STATEFIP (household > geographic), SEX, AGE, and MARST (person > demographic), and LIT (person > education) variables.
Display options: This menu gives a number of options to modify the display of variables when browsing; try out the different options if you’d like.
When finished, click the “VIEW CART” link to go to your data cart. You’ll see the variables that will be returned with your extract.
Figure 11.9: IPUMS data cart
Notice that there will be more variables in your output extract than you selected; this is because a number of technical variables are pre-selected, which is similar to the approach taken by get_pums() in tidycensus. When you are ready to create the extract, click the CREATE DATA EXTRACT button to get a summary of your extract before submitting.
Figure 11.10: IPUMS extract request screen
Note that the example shown reflects changing the output data format to CSV, which will be used to load the IPUMS data into a database. If using R directly for a smaller extract and the ipumsr R package, the default fixed-width text file with the extension .dat can be selected and the data can be read into R with ipumsr::read_ipums_micro(). To replicate the workflow below, however, the output data format should be changed to CSV.
Click SUBMIT EXTRACT to submit your extract request to the IPUMS system. You’ll need to agree to some special usage terms for the 100% data, then wait patiently for your extract to process. You’ll get an email notification when your extract is ready; when you do, return to IPUMS and download your data extract to your computer. The output format will be a gzipped CSV with a prefix unique to your download ID, e.g. usa_00032.csv.gz. Use an appropriate utility to unzip the CSV file.
11.2.2 Loading microdata into a database
Census data analysts may feel comfortable working with .csv files, and reading them into R with readr::read_csv() or one of the many other options for loading data from comma-separated text files. The data extract created in the previous section presents additional challenges for the Census analyst, however. It contains approximately 92.4 million rows - one for each person in the 1910 US Census! This will fill up the memory of a standard laptop computer when read into R very quickly using standard tools.
An alternative solution that can be performed on a standard laptop computer is setting up a database. The solution proposed here uses PostgreSQL, a popular open-source database, and DBeaver, a free cross-platform tool for working with databases.
If PostgreSQL is not already installed on your computer, visit https://www.postgresql.org/download/ and follow the instructions for your operating system to install it. A full tutorial on PostgreSQL for each operating system is beyond the scope of this book, so this example will use standard defaults. When you are finished installing PostgreSQL, you will be prompted to set up a default database, which will be called postgres and will be associated with a user, also named postgres. You’ll be asked to set a password for the database; the examples in this chapter also use postgres for the password, but you can choose whatever password you would like.
Once the default database has been set up, visit https://dbeaver.io/download/ and download/install the appropriate DBeaver Community Edition for your operating system. Launch DBeaver, and look for the “New Database Connection” icon. Click there to launch a connection to your PostgreSQL database. Choose “PostgreSQL” from the menu of database options and fill out your connection settings appropriately.
Figure 11.11: DBeaver connection screen
For most defaults, the host should be localhost running on port 5432 with the database name postgres and the username postgres as well. Enter the password you selected when setting up PostgreSQL and click Finish. You’ll notice your database connection appear in the “Database Navigator” pane of DBeaver.
Within the database, you can create schemas to organize sets of related tables. To create a new schema, right-click the postgres database in the Database Navigator pane and choose “Create > Schema”. This example uses a schema named “ipums”. Within the new schema you’ll be able to import your CSV file as a table. Expand the “ipums” schema and right-click on “Tables” then choose Import Data. Select the unzipped IPUMS CSV file and progress through the menus. This example changes the default “Target” name to census1910.
On the final menu, click the Start button to import your data. Given the size of the dataset, this will likely take some time; it took around 2 hours to prepare the example on my machine. Once the data has imported successfully to the new database table in DBeaver, you’ll be able to inspect your dataset using the DBeaver interface.
Figure 11.12: DBeaver data view
11.2.3 Accessing your microdata database with R
In a typical R workflow with flat files, an analyst will read in a dataset (such as a CSV file) entirely in-memory into R then use their preferred toolset to interact with the data. The alternative discussed in this section involves connecting to the 1910 Census database from R then using R’s database interface toolkit through the tidyverse to analyze the data. A major benefit to this workflow is that it allows an analyst to perform tidyverse operations on datasets in the database. This means that tidyverse functions are translated to Structured Query Language (SQL) queries and passed to the database, with outputs displayed in R, allowing the analyst to interact with data without having to read it into memory.
The first step requires making a database connection from R. The DBI infrastructure for R allows users to make connections to a wide range of databases using a consistent interface (R Special Interest Group on Databases (R-SIG-DB), Wickham, and Müller 2021). The PostgreSQL interface is handled with the RPostgres package (Wickham, Ooms, and Müller 2021).
The dbConnect() function is used to make a database connection, which will be assigned to the object conn. Arguments include the database driver Postgres() and the username, password, database name, host, and port, which are all familiar from the database setup process.
library(tidyverse)
library(RPostgres)
library(dbplyr)
conn <- dbConnect(
drv = Postgres(),
user = "postgres",
password = "postgres",
host = "localhost",
port = "5432",
dbname = "postgres"
)Once connected to the database, the database extension to dplyr, dbplyr, facilitates interaction with database tables (Wickham, Girlich, and Ruiz 2021). tbl() links to the connection object conn to retrieve data from the database; the in_schema() function points tbl() to the census1910 table in the ipums schema.
Printing the new object census1910 shows the general structure of the 1910 Census microdata:
## # Source: table<"ipums"."census1910"> [?? x 13]
## # Database: postgres [postgres@localhost:5433/postgres]
## YEAR sample serial hhwt statefip gq pernum perwt sex age marst lit
## <int> <int> <int> <dbl> <int> <int> <int> <dbl> <int> <int> <int> <int>
## 1 1910 191004 1 1 2 1 1 1 1 43 6 4
## 2 1910 191004 2 1 2 1 1 1 1 34 6 4
## 3 1910 191004 3 1 2 1 1 1 1 41 1 4
## 4 1910 191004 3 1 2 1 2 1 2 39 1 4
## 5 1910 191004 3 1 2 1 3 1 1 37 6 4
## 6 1910 191004 4 1 2 1 1 1 1 24 6 4
## 7 1910 191004 5 1 2 1 1 1 1 24 6 4
## 8 1910 191004 5 1 2 1 2 1 1 35 6 4
## 9 1910 191004 5 1 2 1 3 1 1 45 2 4
## 10 1910 191004 5 1 2 1 4 1 1 55 6 4
## # … with more rows, and 1 more variable: histid <chr>Our data have 13 columns and an unknown number of rows; the database table is so large that dbplyr won’t calculate this automatically. However, the connection to the database allows for interaction with the 1910 Census microdata using familiar tidyverse workflows, which are addressed in the next section.
11.2.4 Analyzing big Census microdata in R
While the default printing of the microdata shown above does not reveal the number of rows in the dataset, tidyverse tools can be used to request this information from the database. For example, the summarize() function will generate summary tabulations as shown earlier in this book; without a companion group_by(), it will do so over the whole dataset.
## # Source: lazy query [?? x 1]
## # Database: postgres [postgres@localhost:5433/postgres]
## `n()`
## <int64>
## 1 92404011There are 92.4 million rows in the dataset, reflecting the US population size in 1910. Given that we are working with complete-count data, the workflow for using microdata differs from the sample data covered in Chapters 9 and 10. While IPUMS by default returns a person-weight column, the value for all rows in the dataset for this column is 1, reflecting a 1:1 relationship between the records and actual people in the United States at that time.
dplyr’s database interface can accommodate more complex examples as well. Let’s say we want to tabulate literacy statistics in 1910 for the population age 18 and up in Texas by sex. A straightforward tidyverse pipeline can accommodate this request to the database. For reference, male is coded as 1 and female as 2, and the literacy codes are as follows:
1: No, illiterate (cannot read or write)
2: Cannot read, can write
3: Cannot write, can read
4: Yes, literate (reads and writes)
## # Source: lazy query [?? x 3]
## # Database: postgres [postgres@localhost:5433/postgres]
## # Groups: sex
## sex lit num
## <int> <int> <int64>
## 1 1 1 115952
## 2 1 2 28
## 3 1 3 14183
## 4 1 4 997844
## 5 2 1 111150
## 6 2 2 16
## 7 2 3 14531
## 8 2 4 883636dbplyr also includes some helper functions to better understand how it is working and to work with the derived results. For example, the show_query() function can be attached to the end of a tidyverse pipeline to show the SQL query that the R code is translated to in order to perform operations in-database:
census1910 %>%
filter(age > 17, statefip == "48") %>%
group_by(sex, lit) %>%
summarize(num = n()) %>%
show_query()## <SQL>
## SELECT "sex", "lit", COUNT(*) AS "num"
## FROM "ipums"."census1910"
## WHERE (("age" > 17.0) AND ("statefip" = '48'))
## GROUP BY "sex", "lit"If an analyst wants the result of a database operation to be brought into R as an R object rather than as a database view, the collect() function can be used at the end of a pipeline to load data directly. A companion function from ipumsr, ipums_collect(), will add variable and value labels to the collected data based on an IPUMS codebook.
The aforementioned toolsets can now be used for robust analyses of historical microdata based on complete-count Census data. The example below illustrates how to extend the literacy by sex example above to visualize literacy gaps by sex by state in 1910.
literacy_props <- census1910 %>%
filter(age > 18) %>%
group_by(statefip, sex, lit) %>%
summarize(num = n()) %>%
group_by(statefip, sex) %>%
mutate(total = sum(num, na.rm = TRUE)) %>%
ungroup() %>%
mutate(prop = num / total) %>%
filter(lit == 4) %>%
collect()
state_names <- tigris::fips_codes %>%
select(state_code, state_name) %>%
distinct()
literacy_props_with_name <- literacy_props %>%
mutate(statefip = str_pad(statefip, 2, "left", "0")) %>%
left_join(state_names, by = c("statefip" = "state_code")) %>%
mutate(sex = ifelse(sex == 1, "Male", "Female"))
ggplot(literacy_props_with_name, aes(x = prop, y = reorder(state_name, prop),
color = sex)) +
geom_line(aes(group = state_name), color = "grey10") +
geom_point(size = 2.5) +
theme_minimal() +
scale_color_manual(values = c(Male = "navy", Female = "darkred")) +
scale_x_continuous(labels = scales::percent) +
labs(x = "Percent fully literate, 1910",
color = "",
y = "")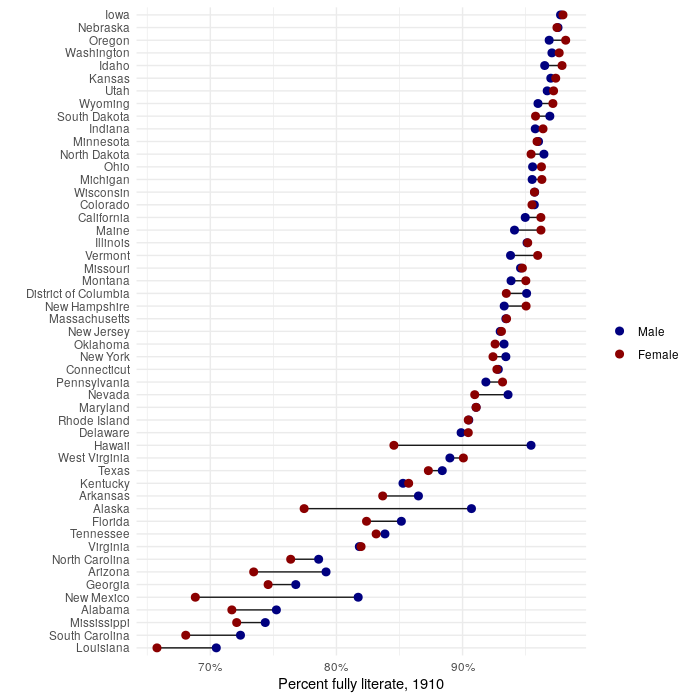
Figure 11.13: Literacy gaps by sex and state in 1910
11.3 Other US government datasets
To this point, this book has focused on a smaller number of US Census Bureau datasets, with a primary focus on the decennial US Census and the American Community Survey. However, many more US government datasets are available to researchers, some from the US Census Bureau and others from different US government agencies. This section covers a series of R packages to help analysts access these resources, and illustrates some applied workflows using those datasets.
11.3.1 Accessing Census data resources with censusapi
censusapi (Recht 2021) is an R package designed to give R users access to all of the US Census Bureau’s API endpoints. Unlike tidycensus, which only focuses on a select number of datasets, censusapi’s getCensus() function can be widely applied to the hundreds of possible datasets the Census Bureau makes available. censusapi requires some knowledge of how to structure Census Bureau API requests to work; however this makes the package more flexible than tidycensus and may be preferable for users who want to submit highly customized queries to the decennial Census or ACS APIs.
censusapi uses the same Census API key as tidycensus, though references it with the R environment variable CENSUS_KEY. If this environment variable is set in a user’s .Renviron file, functions in censusapi will pick up the key without having to supply it directly.
The usethis package (Wickham and Bryan 2021) is the most user-friendly way to work with the .Renviron file in R with its function edit_r_environ(). Calling this function will bring up the .Renviron file in a text editor, allowing users to set environment variables that will be made available to R when R starts up.
Add the line CENSUS_KEY='YOUR KEY HERE' to your .Renviron file, replacing the YOUR KEY HERE text with your API key, then restart R to get access to your key.
censusapi’s core function is getCensus(), which translates R code to Census API queries. The name argument references the API name; the censusapi documentation or the function listCensusApis() helps you understand how to format this.
The example below makes a request to the Economic Census API, getting data on employment and payroll for NAICS code 72 (accommodation and food services businesses) in counties in Texas in 2017.
library(censusapi)
tx_econ17 <- getCensus(
name = "ecnbasic",
vintage = 2017,
vars = c("EMP", "PAYANN", "GEO_ID"),
region = "county:*",
regionin = "state:48",
NAICS2017 = 72
)| state | county | EMP | PAYANN | GEO_ID | NAICS2017 |
|---|---|---|---|---|---|
| 48 | 373 | 1041 | 15256 | 0500000US48373 | 72 |
| 48 | 391 | 246 | 3242 | 0500000US48391 | 72 |
| 48 | 467 | 1254 | 19187 | 0500000US48467 | 72 |
| 48 | 389 | 664 | 14641 | 0500000US48389 | 72 |
| 48 | 473 | 1007 | 16093 | 0500000US48473 | 72 |
| 48 | 485 | 0 | 0 | 0500000US48485 | 72 |
| 48 | 121 | 30380 | 488818 | 0500000US48121 | 72 |
| 48 | 483 | 263 | 3589 | 0500000US48483 | 72 |
| 48 | 215 | 23976 | 329508 | 0500000US48215 | 72 |
| 48 | 105 | 274 | 3118 | 0500000US48105 | 72 |
censusapi can also be used in combination with other packages covered in this book such as tigris for mapping. The example below uses the Small Area Health Insurance Estimates API, which delivers modeled estimates of health insurance coverage at the county level with various demographic breakdowns. Using censusapi and tigris, we can retrieve data on the percent of the population below age 19 without health insurance for all counties in the US. This information will be joined to a counties dataset from tigris with shifted geometry, then mapped with ggplot2.
library(tigris)
library(tidyverse)
us_youth_sahie <- getCensus(
name = "timeseries/healthins/sahie",
vars = c("GEOID", "PCTUI_PT"),
region = "county:*",
regionin = "state:*",
time = 2019,
AGECAT = 4
)
us_counties <- counties(cb = TRUE, resolution = "20m", year = 2019) %>%
shift_geometry(position = "outside") %>%
inner_join(us_youth_sahie, by = "GEOID")
ggplot(us_counties, aes(fill = PCTUI_PT)) +
geom_sf(color = NA) +
theme_void() +
scale_fill_viridis_c() +
labs(fill = "% uninsured ",
caption = "Data source: US Census Bureau Small Area\nHealth Insurance Estimates via the censusapi R package",
title = " Percent uninsured under age 19 by county, 2019")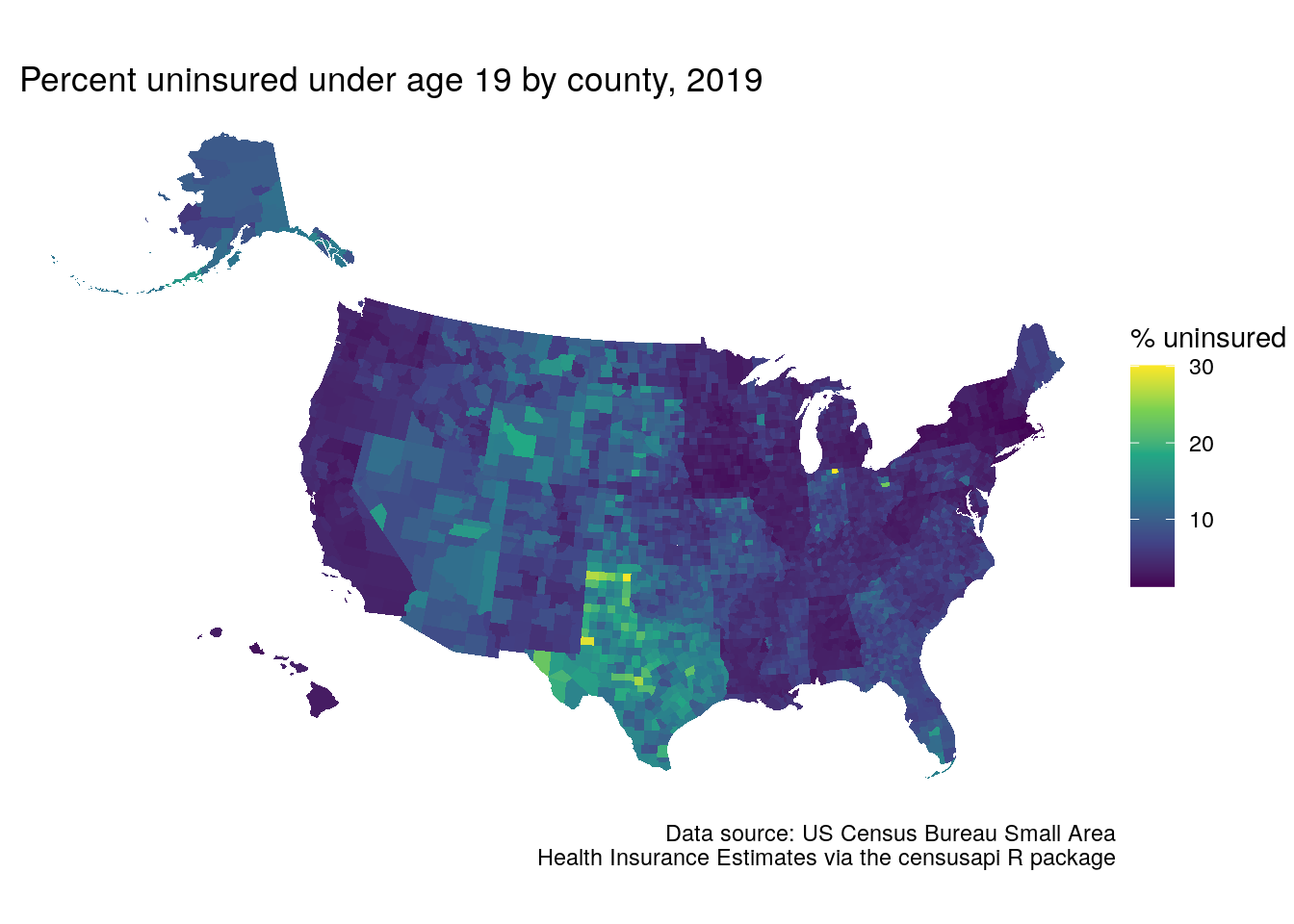
Figure 11.14: Map of youth without health insurance using censusapi and tigris
As these are modeled estimates, state-level influences on the county-level estimates are apparent on the map.
11.3.2 Analyzing labor markets with lehdr
Another very useful package for working with Census Bureau data is the lehdr R package (Green, Wang, and Mahmoudi 2021), which access the Longitudinal and Employer-Household Dynamics (LEHD) Origin-Destination Employment Statistics (LODES) data. LODES is not available from the Census API, meriting an alternative package and approach. LODES includes synthetic estimates of residential, workplace, and residential-workplace links at the Census block level, allowing for highly detailed geographic analysis of jobs and commuter patterns over time.
The core function implemented in lehdr is grab_lodes(), which downloads a LODES file of a specified lodes_type (either "rac" for residential, "wac" for workplace, or "od" for origin-destination) for a given state and year. While the raw LODES data are available at the Census block level, the agg_geo parameter offers a convenient way to roll up estimates to higher levels of aggregation. For origin-destination data, the state_part = "main" argument below captures within-state commuters; use state_part = "aux" to get commuters from out-of-state. The optional argument use_cache = TRUE stores downloaded LODES data in a cache directory on the user’s computer; this is recommended to avoid having to re-download data for future analyses.
library(lehdr)
library(tidycensus)
library(sf)
library(tidyverse)
library(tigris)
wa_lodes_od <- grab_lodes(
state = "wa",
year = 2018,
lodes_type = "od",
agg_geo = "tract",
state_part = "main",
use_cache = TRUE
)The result is a dataset that shows tract-to-tract commute flows (S000) and broken down by a variety of characteristics, referenced in the LODES documentation.
| year | state | w_tract | h_tract | S000 | SA01 | SA02 | SA03 | SE01 | SE02 | SE03 | SI01 | SI02 | SI03 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2018 | WA | 53001950100 | 53001950100 | 515 | 109 | 241 | 165 | 203 | 170 | 142 | 31 | 91 | 393 |
| 2018 | WA | 53001950100 | 53001950200 | 75 | 12 | 40 | 23 | 16 | 41 | 18 | 8 | 5 | 62 |
| 2018 | WA | 53001950100 | 53001950300 | 23 | 2 | 20 | 1 | 0 | 3 | 20 | 1 | 3 | 19 |
| 2018 | WA | 53001950100 | 53001950400 | 13 | 3 | 6 | 4 | 1 | 6 | 6 | 0 | 0 | 13 |
| 2018 | WA | 53001950100 | 53001950500 | 27 | 5 | 18 | 4 | 1 | 18 | 8 | 1 | 0 | 26 |
| 2018 | WA | 53001950100 | 53003960100 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| 2018 | WA | 53001950100 | 53003960300 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 |
| 2018 | WA | 53001950100 | 53003960400 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 2018 | WA | 53001950100 | 53003960500 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 2018 | WA | 53001950100 | 53005010201 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
lehdr can be used for a variety of purposes including transportation and economic development planning. For example, the workflow below illustrates how to use LODES data to understand the origins of commuters to the Microsoft campus (represented by its Census tract) in Redmond, Washington. Commuters from LODES will be normalized by the total population age 18 and up, acquired with tidycensus for 2018 Census tracts in Seattle-area counties. The dataset ms_commuters will include Census tract geometries (obtained with geometry = TRUE in tidycensus) and an estimate of the number of Microsoft-area commuters per 1000 adults in that Census tract.
seattle_adults <- get_acs(
geography = "tract",
variables = "S0101_C01_026",
state = "WA",
county = c("King", "Kitsap", "Pierce",
"Snohomish"),
year = 2018,
geometry = TRUE
)
microsoft <- filter(wa_lodes_od, w_tract == "53033022803")
ms_commuters <- seattle_adults %>%
left_join(microsoft, by = c("GEOID" = "h_tract")) %>%
mutate(ms_per_1000 = 1000 * (S000 / estimate)) %>%
st_transform(6596) %>%
erase_water(area_threshold = 0.99)The result can be visualized on a map with ggplot2, or alternatively with any of the mapping tools introduced in Chapter 6. Note the use of the erase_water() function from the tigris package introduced in Section 7.5 with a high area threshold to remove large bodies of water like Lake Washington from the Census tract shapes.
ggplot(ms_commuters, aes(fill = ms_per_1000)) +
geom_sf(color = NA) +
theme_void() +
scale_fill_viridis_c(option = "cividis") +
labs(title = "Microsoft commuters per 1000 adults",
subtitle = "2018 LODES data, Seattle-area counties",
fill = "Rate per 1000")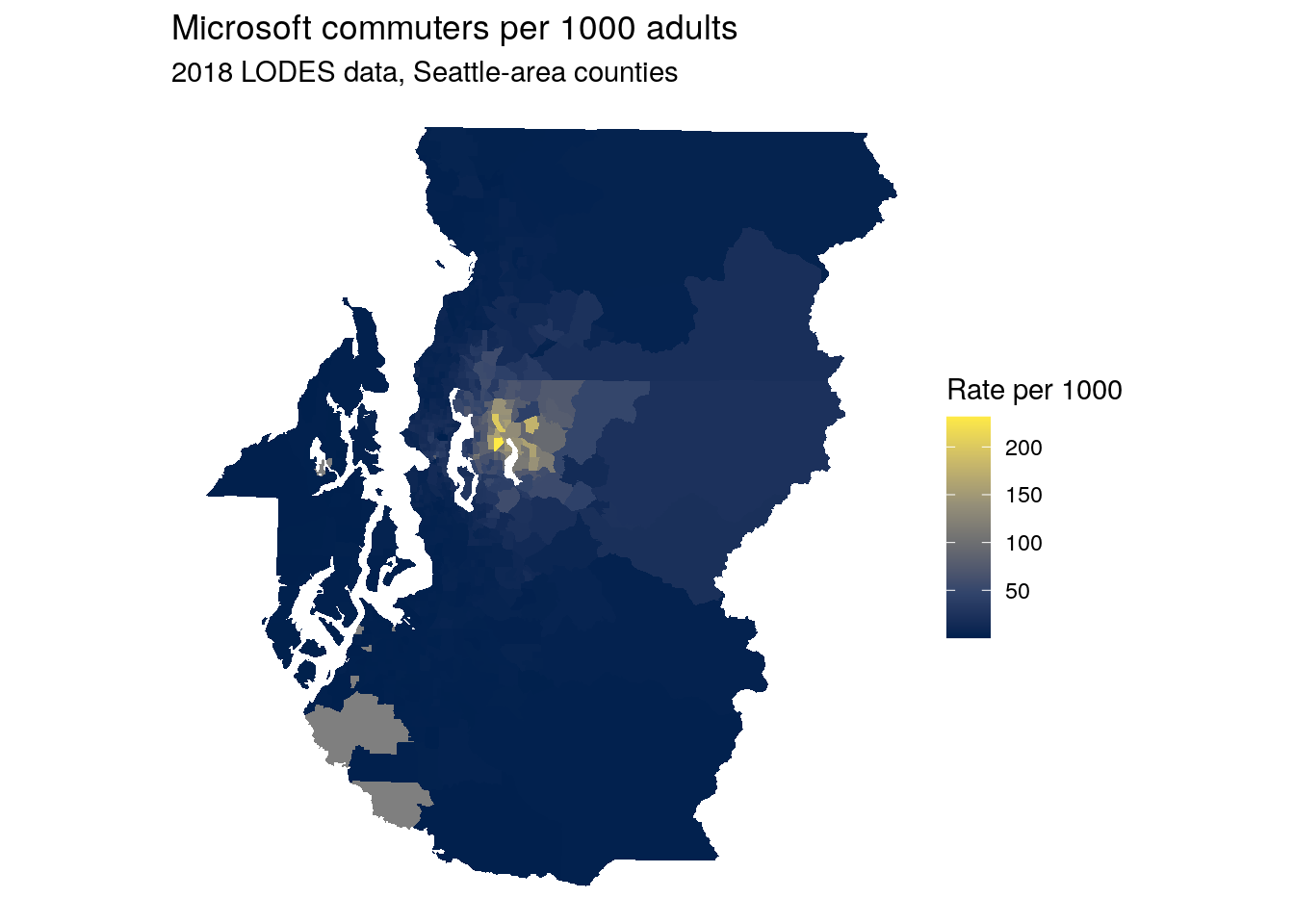
Figure 11.15: Map of commuter origins to the Microsoft Campus area, Seattle-area counties
11.3.3 Bureau of Labor Statistics data with blscrapeR
Another essential resource for data on US labor market characteristics is the Bureau of Labor Statistics, which makes their data available to users via an API. BLS data can be accessed from R with the blscrapeR package (Eberwein 2021). Like other government APIs, the BLS API requires an API key, obtained from https://data.bls.gov/registrationEngine/. Sign up with an email address then validate the key using the link sent to your email, then return to R to get started with blscrapeR.
# remotes::install_github("keberwein/blscrapeR")
library(blscrapeR)
set_bls_key("YOUR KEY HERE")blscrapeR includes a number of helper functions to assist users with some of the most commonly requested statistics. For example, the get_bls_county() function fetches employment data for all counties in the US for a given month.
latest_employment <- get_bls_county("May 2022")| area_code | fips_state | fips_county | area_title | period | labor_force | employed | unemployed | unemployed_rate | fips |
|---|---|---|---|---|---|---|---|---|---|
| CN0100100000000 | 01 | 001 | Autauga County, AL | 2022-05-01 | 26916 | 26362 | 554 | 2.1 | 01001 |
| CN0100300000000 | 01 | 003 | Baldwin County, AL | 2022-05-01 | 101761 | 99568 | 2193 | 2.2 | 01003 |
| CN0100500000000 | 01 | 005 | Barbour County, AL | 2022-05-01 | 8220 | 7920 | 300 | 3.6 | 01005 |
| CN0100700000000 | 01 | 007 | Bibb County, AL | 2022-05-01 | 8769 | 8574 | 195 | 2.2 | 01007 |
| CN0100900000000 | 01 | 009 | Blount County, AL | 2022-05-01 | 25868 | 25356 | 512 | 2.0 | 01009 |
| CN0101100000000 | 01 | 011 | Bullock County, AL | 2022-05-01 | 4469 | 4346 | 123 | 2.8 | 01011 |
| CN0101300000000 | 01 | 013 | Butler County, AL | 2022-05-01 | 8759 | 8451 | 308 | 3.5 | 01013 |
| CN0101500000000 | 01 | 015 | Calhoun County, AL | 2022-05-01 | 46602 | 45262 | 1340 | 2.9 | 01015 |
| CN0101700000000 | 01 | 017 | Chambers County, AL | 2022-05-01 | 15887 | 15509 | 378 | 2.4 | 01017 |
| CN0101900000000 | 01 | 019 | Cherokee County, AL | 2022-05-01 | 11683 | 11440 | 243 | 2.1 | 01019 |
More complex queries are also possible with the bls_api() function; however, this requires knowing the BLS series ID. Series IDs are composite strings made up of several alphanumeric codes that can represent different datasets, geographies, and industries, among others. blscrapeR includes an internal dataset, series_ids, to help users view some of the most commonly requested IDs.
head(series_ids)| series_title | series_id | seasonal | periodicity_code |
|---|---|---|---|
| (Seas) Population Level | LNS10000000 | S | M |
| (Seas) Population Level | LNS10000000Q | S | Q |
| (Seas) Population Level - Men | LNS10000001 | S | M |
| (Seas) Population Level - Men | LNS10000001Q | S | Q |
| (Seas) Population Level - Women | LNS10000002 | S | M |
| (Seas) Population Level - Women | LNS10000002Q | S | Q |
series_ids only contains indicators from the Current Population Survey and Local Area Unemployment Statistics databases. Other data series can be constructed by following the instructions on <https://www.bls.gov/help/hlpforma.htm>. The example below illustrates this for data on the Current Employment Statistics, for which the series ID is formatted as follows:
Positions 1-2: The prefix (in this example,
SA)Position 3: The seasonal adjustment code (either
S, for seasonally adjusted, orU, for unadjusted)Positions 4-5: The two-digit state FIPS code
Positions 6-10: The five-digit area code, which should be set to
00000if an entire state is requested.Positions 11-18: The super sector/industry code
Positions 19-20: The data type code
We’ll use this information to get unadjusted data on accommodation workers in Maui, Hawaii since the beginning of 2018. Note that the specific codes detailed above will vary from indicator to indicator, and that not all industries will be available for all geographies.
maui_accom <- bls_api(seriesid = "SMU15279807072100001",
startyear = 2018)| year | period | periodName | latest | value | footnotes | seriesID |
|---|---|---|---|---|---|---|
| 2022 | M12 | December | true | 12.2 | P Preliminary | SMU15279807072100001 |
| 2022 | M11 | November | NA | 12.3 | SMU15279807072100001 | |
| 2022 | M10 | October | NA | 12.2 | SMU15279807072100001 | |
| 2022 | M09 | September | NA | 12.1 | SMU15279807072100001 | |
| 2022 | M08 | August | NA | 12.2 | SMU15279807072100001 | |
| 2022 | M07 | July | NA | 12.1 | SMU15279807072100001 |
This time series can be visualized with ggplot2:
maui_accom %>%
mutate(period_order = rev(1:nrow(.))) %>%
ggplot(aes(x = period_order, y = value, group = 1)) +
geom_line(color = "darkgreen") +
theme_minimal() +
scale_y_continuous(limits = c(0, max(maui_accom$value) + 1)) +
scale_x_continuous(breaks = seq(1, 54, 12),
labels = paste("Jan", 2018:2022)) +
labs(x = "",
y = "Number of jobs (in 1000s)",
title = "Accommodation employment in Maui, Hawaii",
subtitle = "Data source: BLS Current Employment Statistics")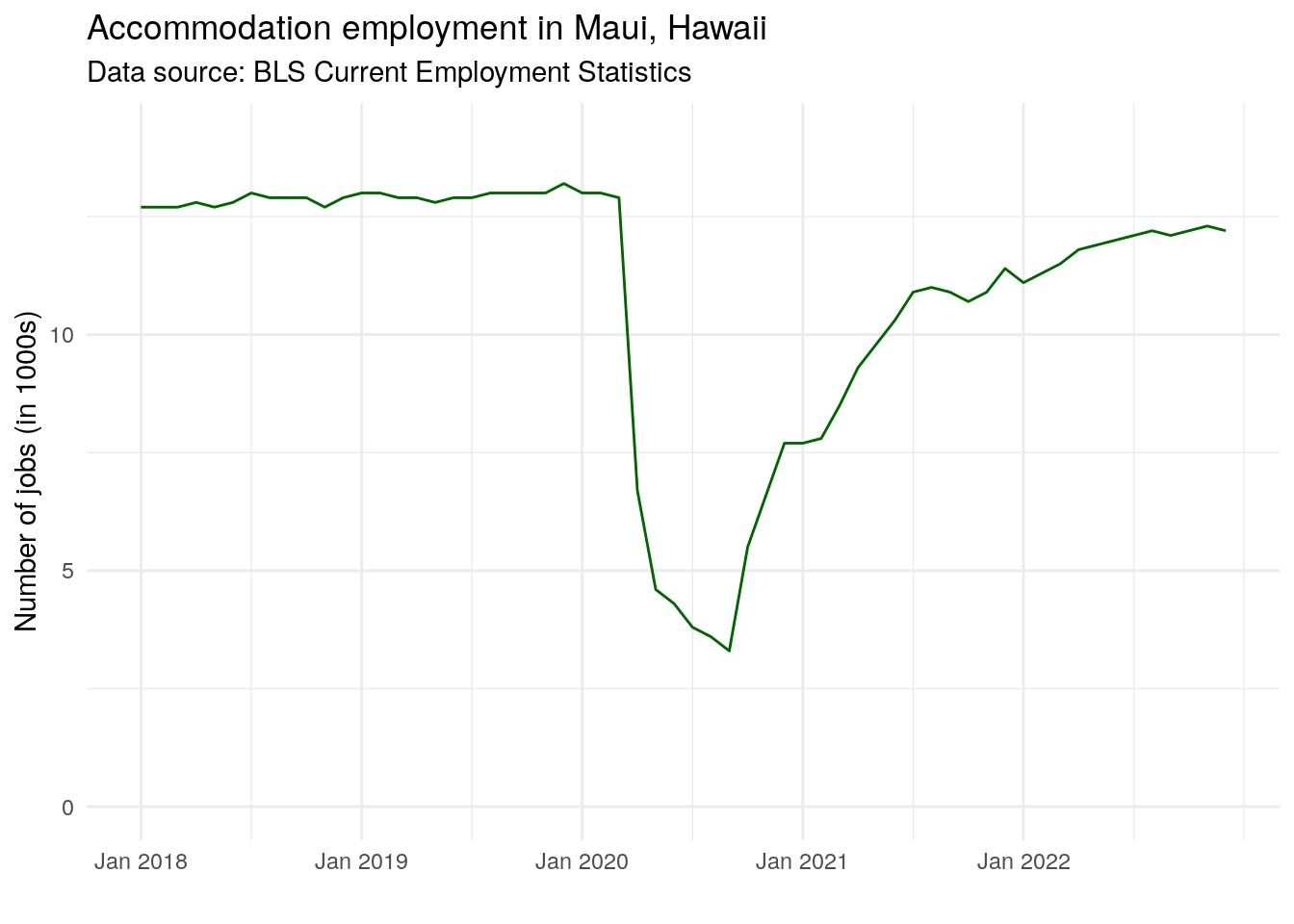
Figure 11.16: Time-series of accommodations employment in Maui, Hawaii
The data suggest a stable accommodations sector prior to the onset of the COVID-19 pandemic, with recovery in the industry starting toward the end of 2020.
11.3.4 Working with agricultural data with tidyUSDA
Agriculture can be a difficult sector on which to collect market statistics, as it is not available in many data sources such as LODES or the BLS Current Employment Statistics. Dedicated statistics on US agriculture can be acquired with the tidyUSDA R package (Lindblad 2021), which interacts with USDA data resources using tidyverse-centric workflows. Get an API key at https://quickstats.nass.usda.gov/api and use that to request data from the USDA QuickStats API. In this example, the API key is stored as a "USDA_KEY" environment variable.
library(tidyUSDA)
usda_key <- Sys.getenv("USDA_KEY")Now, let’s see which US counties produce have the most acres devoted to cucumbers. To use the getQuickstat() function effectively, it is helpful to construct a query first at https://quickstats.nass.usda.gov/ and see what options are available, then bring those options as arguments into R.
cucumbers <- getQuickstat(
key = usda_key,
program = "CENSUS",
data_item = "CUCUMBERS, FRESH MARKET - ACRES HARVESTED",
sector = "CROPS",
group = "VEGETABLES",
commodity = "CUCUMBERS",
category = "AREA HARVESTED",
domain = "TOTAL",
geographic_level = "COUNTY",
year = "2017"
)This information allows us to look at the top cucumber-growing counties in the US:
| state_name | county_name | Value |
|---|---|---|
| FLORIDA | MANATEE | 2162 |
| MICHIGAN | BERRIEN | 1687 |
| CALIFORNIA | SAN JOAQUIN | 1558 |
| GEORGIA | BROOKS | 1495 |
| NORTH CAROLINA | SAMPSON | 1299 |
| FLORIDA | HILLSBOROUGH | 1070 |
| MICHIGAN | BAY | 453 |
| NEW JERSEY | GLOUCESTER | 438 |
11.4 Getting government data without R packages
The breath of R’s developer ecosystem means that in many cases if you have a need for US government data, an enterprising developer has written some code that you can use. However, this won’t be true for every data resource, especially as US government agencies continue to release new API endpoints to open up access to data. In this case, you may be interested in writing your own data access functions for this purpose. This section gives some pointers on how to make HTTP requests to data APIs using the httr package and process the data appropriately for use in R.
11.4.1 Making requests to APIs with httr
Most data API packages in R will rely on the httr R package (Wickham 2020), which provides R functions for common HTTP requests such as GET, POST, and PUT, among others. In this example, we’ll use the httr::GET() function to make a request to the new Department of Housing and Urban Development Comprehensive Affordable Housing Strategy (CHAS) API. This will require getting a HUD API token and storing it as an environment variable as described earlier in this chapter.
Every API will be structured differently with respect to how it accepts queries and authenticates with API tokens. In this example, the documentation instructs users to pass the API token in the HTTP request with the Authentication: Bearer header. The example URL in the documentation, https://www.huduser.gov/hudapi/public/chas?type=3&year=2012-2016&stateId=51&entityId=59, is passed to GET(), and the add_headers() function in httr is used to assemble an appropriate string to send to the API.
library(glue)
library(httr)
library(jsonlite)
library(tidyverse)
my_token <- Sys.getenv("HUD_TOKEN")
hud_chas_request <- GET("https://www.huduser.gov/hudapi/public/chas?type=3&year=2012-2016&stateId=51&entityId=59",
add_headers(Authorization = glue("Bearer {my_token}")))
hud_chas_request$status_code## [1] 200As we got back the HTTP status code 200, we know that our request to the API succeeded. To view the returned data, we use the content() function and translate the result to text with the as = "text" argument.
content(hud_chas_request, as = "text")## [1] "[{\"geoname\":\"Fairfax County, Virginia\",\"sumlevel\":\"County\",\"year\":\"2012-2016\",\"A1\":\"12895.0\",\"A2\":\"21805.0\",\"A3\":\"34700.0\",\"A4\":\"14165.0\",\"A5\":\"17535.0\",\"A6\":\"31700.0\",\"A7\":\"10690.0\",\"A8\":\"10350.0\",\"A9\":\"21040.0\",\"A10\":\"16890.0\",\"A11\":\"14325.0\",\"A12\":\"31215.0\",\"A13\":\"210710.0\",\"A14\":\"63990.0\",\"A15\":\"274700.0\",\"A16\":\"265350.0\",\"A17\":\"128005.0\",\"A18\":\"393360.0\",\"B1\":\"58925.0\",\"B2\":\"57735.0\",\"B3\":\"116660.0\",\"B4\":\"205390.0\",\"B5\":\"68400.0\",\"B6\":\"273790.0\",\"B7\":\"1035.0\",\"B8\":\"1875.0\",\"B9\":\"2910.0\",\"C1\":\"23945.0\",\"C2\":\"31650.0\",\"C3\":\"55595.0\",\"C4\":\"240370.0\",\"C5\":\"94480.0\",\"C6\":\"334850.0\",\"D1\":\"207915.0\",\"D2\":\"73630.0\",\"D3\":\"281545.0\",\"D4\":\"35735.0\",\"D5\":\"28910.0\",\"D6\":\"64645.0\",\"D7\":\"20670.0\",\"D8\":\"23405.0\",\"D9\":\"44075.0\",\"D10\":\"1035.0\",\"D11\":\"2060.0\",\"D12\":\"3095.0\",\"E1\":\"28030.0\",\"E2\":\"3760.0\",\"E3\":\"2910.0\",\"E5\":\"25945.0\",\"E6\":\"5755.0\",\"E7\":\"0.0\",\"E9\":\"14305.0\",\"E10\":\"6735.0\",\"E11\":\"0.0\",\"E13\":\"16085.0\",\"E14\":\"15135.0\",\"E15\":\"0.0\",\"E17\":\"32295.0\",\"E18\":\"242405.0\",\"E19\":\"0.0\",\"E21\":\"116660.0\",\"E22\":\"273790.0\",\"E23\":\"2910.0\",\"F1\":\"17265.0\",\"F2\":\"2665.0\",\"F3\":\"1875.0\",\"F5\":\"15720.0\",\"F6\":\"1815.0\",\"F7\":\"0.0\",\"F9\":\"8165.0\",\"F10\":\"2185.0\",\"F11\":\"0.0\",\"F13\":\"7900.0\",\"F14\":\"6430.0\",\"F15\":\"0.0\",\"F17\":\"8685.0\",\"F18\":\"55305.0\",\"F19\":\"0.0\",\"F21\":\"57735.0\",\"F22\":\"68400.0\",\"F23\":\"1875.0\",\"G1\":\"10765.0\",\"G2\":\"1095.0\",\"G3\":\"1035.0\",\"G5\":\"10225.0\",\"G6\":\"3940.0\",\"G7\":\"0.0\",\"G9\":\"6140.0\",\"G10\":\"4550.0\",\"G11\":\"0.0\",\"G13\":\"8185.0\",\"G14\":\"8705.0\",\"G15\":\"0.0\",\"G17\":\"23610.0\",\"G18\":\"187100.0\",\"G19\":\"0.0\",\"H1\":\"27605.0\",\"H2\":\"23420.0\",\"H4\":\"24970.0\",\"H5\":\"12660.0\",\"H7\":\"13465.0\",\"H8\":\"3470.0\",\"H10\":\"14930.0\",\"H11\":\"2060.0\",\"H13\":\"27750.0\",\"H14\":\"2460.0\",\"H16\":\"108720.0\",\"I1\":\"16895.0\",\"I2\":\"14490.0\",\"I4\":\"14970.0\",\"I5\":\"7115.0\",\"I7\":\"7550.0\",\"I8\":\"1180.0\",\"I10\":\"7000.0\",\"I11\":\"425.0\",\"I13\":\"5900.0\",\"I14\":\"195.0\",\"I16\":\"52315.0\",\"J1\":\"10705.0\",\"J2\":\"8930.0\",\"J4\":\"10005.0\",\"J5\":\"5550.0\",\"J7\":\"5915.0\",\"J8\":\"2290.0\",\"J10\":\"7930.0\",\"J11\":\"1635.0\",\"J13\":\"21850.0\",\"J14\":\"2265.0\",\"J16\":\"56405.0\"}]"The data were returned as JavaScript Object Notation, or JSON, a very common data format for returning data from APIs. While the data shown above is moderately interpretable, it will require some additional translation for use in R. The jsonlite package (Ooms 2014) includes a poewrful set of tools for working with JSON objects in R; here, we’ll use the fromJSON() function to convert JSON to a data frame.
| geoname | sumlevel | year | A1 | A2 | A3 | A4 | A5 | A6 | A7 | A8 | A9 | A10 | A11 | A12 | A13 | A14 | A15 | A16 | A17 | A18 | B1 | B2 | B3 | B4 | B5 | B6 | B7 | B8 | B9 | C1 | C2 | C3 | C4 | C5 | C6 | D1 | D2 | D3 | D4 | D5 | D6 | D7 | D8 | D9 | D10 | D11 | D12 | E1 | E2 | E3 | E5 | E6 | E7 | E9 | E10 | E11 | E13 | E14 | E15 | E17 | E18 | E19 | E21 | E22 | E23 | F1 | F2 | F3 | F5 | F6 | F7 | F9 | F10 | F11 | F13 | F14 | F15 | F17 | F18 | F19 | F21 | F22 | F23 | G1 | G2 | G3 | G5 | G6 | G7 | G9 | G10 | G11 | G13 | G14 | G15 | G17 | G18 | G19 | H1 | H2 | H4 | H5 | H7 | H8 | H10 | H11 | H13 | H14 | H16 | I1 | I2 | I4 | I5 | I7 | I8 | I10 | I11 | I13 | I14 | I16 | J1 | J2 | J4 | J5 | J7 | J8 | J10 | J11 | J13 | J14 | J16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fairfax County, Virginia | County | 2012-2016 | 12895.0 | 21805.0 | 34700.0 | 14165.0 | 17535.0 | 31700.0 | 10690.0 | 10350.0 | 21040.0 | 16890.0 | 14325.0 | 31215.0 | 210710.0 | 63990.0 | 274700.0 | 265350.0 | 128005.0 | 393360.0 | 58925.0 | 57735.0 | 116660.0 | 205390.0 | 68400.0 | 273790.0 | 1035.0 | 1875.0 | 2910.0 | 23945.0 | 31650.0 | 55595.0 | 240370.0 | 94480.0 | 334850.0 | 207915.0 | 73630.0 | 281545.0 | 35735.0 | 28910.0 | 64645.0 | 20670.0 | 23405.0 | 44075.0 | 1035.0 | 2060.0 | 3095.0 | 28030.0 | 3760.0 | 2910.0 | 25945.0 | 5755.0 | 0.0 | 14305.0 | 6735.0 | 0.0 | 16085.0 | 15135.0 | 0.0 | 32295.0 | 242405.0 | 0.0 | 116660.0 | 273790.0 | 2910.0 | 17265.0 | 2665.0 | 1875.0 | 15720.0 | 1815.0 | 0.0 | 8165.0 | 2185.0 | 0.0 | 7900.0 | 6430.0 | 0.0 | 8685.0 | 55305.0 | 0.0 | 57735.0 | 68400.0 | 1875.0 | 10765.0 | 1095.0 | 1035.0 | 10225.0 | 3940.0 | 0.0 | 6140.0 | 4550.0 | 0.0 | 8185.0 | 8705.0 | 0.0 | 23610.0 | 187100.0 | 0.0 | 27605.0 | 23420.0 | 24970.0 | 12660.0 | 13465.0 | 3470.0 | 14930.0 | 2060.0 | 27750.0 | 2460.0 | 108720.0 | 16895.0 | 14490.0 | 14970.0 | 7115.0 | 7550.0 | 1180.0 | 7000.0 | 425.0 | 5900.0 | 195.0 | 52315.0 | 10705.0 | 8930.0 | 10005.0 | 5550.0 | 5915.0 | 2290.0 | 7930.0 | 1635.0 | 21850.0 | 2265.0 | 56405.0 |
The data are now formatted as an R data frame which can be embedded in your R-based workflows.
11.4.2 Writing your own data access functions
If you plan to use a particular API endpoint frequently, or for different areas and times, it is a good idea to write a data access function. API functions should ideally identify the components of the API request that can vary, and allow users to make modifications in ways that correspond to those components.
The URL used in the example above can be separated into two components: the API endpoint https://www.huduser.gov/hudapi/public/chas, which will be common to all API requests, and the query ?type=3&year=2012-2016&stateId=51&entityId=59, which shows components of the request that can vary. The query will generally follow a question mark sign and be composed of key-value pairs, e.g. type=3, which in this example means county according to the HUD API documentation. These queries can be passed as a list to the query parameter of GET() and formatted appropriately in the HTTP request by httr.
The function below is an example you can use to get started writing your own API data request functions. The general components of the function are as follows:
The function is defined by a name,
get_hud_chas(), with a number of parameters to which the user will supply arguments. Default arguments can be specified (e.g.year = "2013-2017"to request that data without the user needing to specify it directly. If a default argument isNULL, it will be ignored by theGET()request.The function first checks to see if an existing HUD token exists in the user’s environment referenced by the name
HUD_TOKENif the user hasn’t supplied it directly.Next, the function constructs the
GET()query, translating the function arguments to an HTTP query.If the request has failed, the function returns the error message from the API to help inform the user about what went wrong.
If the request succeeds, the function converts the result to text, then the JSON to a data frame which will be pivoted to long form using tidyr’s
pivot_longer()function. Finally, the result is returned. I use thereturn()function here, which isn’t strictly necessary but I use it because it is helpful for me to see where the function exits in my code.You may notice a couple new notational differences from code used elsewhere in this book. Functions are referenced with the
packagename::function()notation, and the new base R pipe|>is used instead of the magrittr pipe%>%. This allows the function to run without loading any external libraries withlibrary(), which is generally a good idea when writing functions to avoid namespace conflicts.
get_hud_chas <- function(
type,
year = "2013-2017",
state_id = NULL,
entity_id = NULL,
token = NULL
) {
# Check to see if a token exists
if (is.null(token)) {
if (Sys.getenv("HUD_TOKEN") != "") {
token <- Sys.getenv("HUD_TOKEN")
}
}
# Specify the base URL
base_url <- "https://www.huduser.gov/hudapi/public/chas"
# Make the query
hud_query <- httr::GET(
base_url,
httr::add_headers(Authorization = glue::glue("Bearer {token}")),
query = list(
type = type,
year = year,
stateId = state_id,
entityId = entity_id)
)
# Return the HTTP error message if query failed
if (hud_query$status_code != "200") {
msg <- httr::content(hud_query, as = "text")
return(msg)
}
# Return the content as text
hud_content <- httr::content(hud_query, as = "text")
# Convert the data to a long-form tibble
hud_tibble <- hud_content |>
jsonlite::fromJSON() |>
dplyr::as_tibble() |>
tidyr::pivot_longer(cols = !dplyr::all_of(c("geoname", "sumlevel", "year")),
names_to = "indicator",
values_to = "value")
return(hud_tibble)
}Now, let’s try out the function for a different locality in Virginia:
get_hud_chas(type = 3, state_id = 51, entity_id = 510)| geoname | sumlevel | year | indicator | value |
|---|---|---|---|---|
| Alexandria city, Virginia | County | 2013-2017 | A1 | 1185.0 |
| Alexandria city, Virginia | County | 2013-2017 | A2 | 6745.0 |
| Alexandria city, Virginia | County | 2013-2017 | A3 | 7930.0 |
| Alexandria city, Virginia | County | 2013-2017 | A4 | 1335.0 |
| Alexandria city, Virginia | County | 2013-2017 | A5 | 5355.0 |
| Alexandria city, Virginia | County | 2013-2017 | A6 | 6690.0 |
| Alexandria city, Virginia | County | 2013-2017 | A7 | 1245.0 |
| Alexandria city, Virginia | County | 2013-2017 | A8 | 3580.0 |
| Alexandria city, Virginia | County | 2013-2017 | A9 | 4825.0 |
| Alexandria city, Virginia | County | 2013-2017 | A10 | 1465.0 |
The function returns affordable data for Alexandria, Virginia in a format that is more suitable for use with tidyverse tools.
11.5 Exercises
Visit https://ipums.org and spend some time exploring NHGIS and/or IPUMS. Attempt to replicate the NHGIS workflow for a different variable and time period.
Explore the censusapi package and create a request to a Census API endpoint using a dataset that you weren’t previously familiar with. Join the data to shapes you’ve obtained with tigris and make a map of your data.